
Shell codes, what are they and what do they do?
Today we are going to talk about one of the types of malicious instructions exploiting remote software vulnerabilities, particularly memory vulnerabilities. Historically, such sets of instructions are called shell codes. Previously such attacks used to grant access to shell, and somehow it became the custom. Typical memory vulnerabilities exploited by shell codes are, first of all, buffer overrun, stock variables and other structures overrun.
Let’s view them in layman’s terms, taking the simplest type as an example. Stack buffer overrun is considered the simplest one. So, shell codes operate as follows. Let’s assume that some vulnerable function working with user data was activated in the code. When it is activated, the stack undergoes several things at once: the return address to the following instruction is kept there (in order to know where the control should be passed to after the vulnerable function ends); ‘BP’ flag value is kept; a specific area for local data is allocated (which in our case is the “user input”). If the number of functions read is not verified, but the malefactor has transferred more data than it is necessary, then this data will replace service values in the stack, both flag values and return address. Where will the control go after the function has been ended? It will go to the very address that now has appeared in the return address area. Thus, the malefactor’s target task is to form the data in such a way in order to pass the control to the malicious load that also resides in the data transferred. Basically, to run a random code on a victim machine.
Traditionally, both shell codes and methods of their detection are usually associated with x86 platform due to the fact that this type of attack is rather old and used to target the most popular platform. The situation has changed for the past several years. ARM-based devices are several times more popular than x86 now and continue growing in number. This means both smartphones and tablets; Google and Samsung are producing ARM-based chomebooks now. ARM architecture (Advanced RISC Machine) is a family of licensed 32bit and 64bit microprocessor cores designed by ARM Limited. ARM presents a processor RISC architecture. Both the platform and shell codes seem to be on several different levels of abstraction. How can platform replacement change the shell code type? The answer is hidden in the number of essential differences between the two platforms which give the malefactors an opportunity to use varied techniques for shell coding.
What was wrong with ARM
The current shell code detection solutions available for x86 platform analyze typical shell code features. Nevertheless, they appear to be inapplicable for ARM platform as the shell code types change. Let’s look at the differences between these two architectures more closely, as they directly influence the shell code types.
Fixed instruction size
Apart from x86 architecture, where the size of instructions varies from one to 16bit, all the instructions in ARM architecture are of fixed size (32bit for ARM mode, 16bit for Thumb).
Due to this ARM feature, the disassembly with different offsets is not synchronized (self-synchronizing disassembly). Self-synchronizing disassembly is a disassembling feature for instructions in x86 architecture. No matter what byte it starts with, there will always be a synchronization point between a random byte disassembly and the beginning of an instruction stream disassembly. This feature simplifies shell code search within the traffic (it may be located randomly in the stream), but makes it harder to run shell code analysis, as there is a risk to miss instructions which are critical for the shell code (see pic. 2).
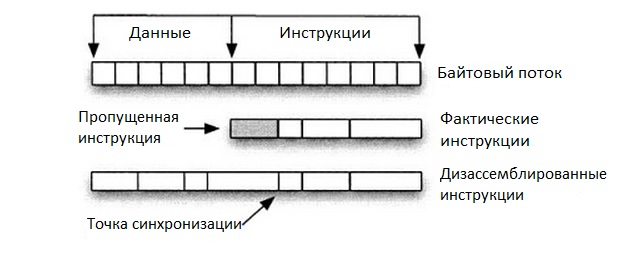
Pic. 2. Self-synchronizing disassembly
When detecting ARM shell codes within the byte stream it is enough to perform disassembly starting with four offsets from the beginning of the stream: 0, 1, 2, 3. As the instructions are fixed in length, the disassembling process will always start from the beginning of the shell code without skipping important instructions.
Several work modes of the processor and dynamical change among them
We have already mentioned two processor modes. It’s even more complex in reality: besides those two we’ve got Thumb2 (several 32bit instructions were added to 16bit Thumb; such technique allows to increase the opcode density significantly) and Jazelle supporting hardware acceleration for Java byte code.
Thumb mode, in particular, usually was used to make programs to fit in the integrated systems for which limited storage is typical. The use of Thumb under other conditions is not reasonable, as it is slower than ARM mode: it doesn’t support conditional execution, jump prediction module doesn’t perform really well, etc. Due to this fact most applications use ARM mode, but with shell coding the problem of data volume becomes topical issue. That is why dynamic processor mode change is one of the most popular techniques for shell codes. Particularly, It is presented in more than 80% of publicly available templates. An example of a shell code written with different processor modes is shown on pic. 3.
The change is performed with jump instructions:
- jump on ‘label’ mark and switching to a different mode;
- jump on address written to ‘Rm’ registry;
- mode changing depending on the value of the last registry byte (0 — ARM, 1 — Thumb).
The procedure is as follows. An instruction to change processor mode appears in the shell codes (‘BX Rm’) on the crossing of instruction chain from different processor modes. As the vulnerable program may run in ARM mode, then in order to execute the shell code, the processor has to be switched to Thumb mode. In order to switch the processor to another mode, it is necessary to read the instruction counter register and use its value to jump to the beginning of the shell code with the help of BX Rm instruction, where ‘Rm’ is a general purpose register with the address of the shell code beginning written in. In order to tell the processor which mode it should change to, a value depending on the mode required will be put into the most significant bit of the address.
The instructions from different modes may be located at some distance from one another, but subject to shell code limitations we may assume that offset between the ARM processor mode change code and Thumb shell code will be comparable with the shell code size. An example of such shell code can be seen on pic. 4 (this shell code was taken from exploit-db.com).
The dynamic processor mode changing technique is used in shell codes not only to implement wider functionality into the same size but also for obfuscation as well. Apparently, the process mode change and, respectively, other disassembly will lead to failure in execution of signature approaches on the same template. From the other hand, if you know about this special feature, nobody will prevent you from generating all the possible signatures with processor mode changes taken into account. Nevertheless, nobody has ever focused on this issue.
Conditional execution of instructions
In our opinion it’s one of the most interesting ARM features that introduces another shell code obfuscation method. Each instruction in ARM is executed or ignored by the processor depending on the flag register value. The flag register value for an instruction to be executed is selected through adding a specific suffix to the instruction.
For example, MOVEQ R0, R0 instruction will only be executed with Z = 1 flag (‘EQ’ suffix is used). There exist 15 suffix values. And there is also ‘S’ suffix that indicates whether or not this instruction will change flag register value.
What is this technique for shell codes? First, through this you can reduce code volume significantly (see pic. 5). Second, a new type of obfuscation is now possible: what if we provide an absolutely legitimate program with malicious load only through replacement of flag values with the ones we need? Such a method will obviously hamper the static analysis. For example, one of typical and rather efficient approaches to static analysis is varied analysis of control flow graphs (CFG) and instruction flow graphs (IFG).
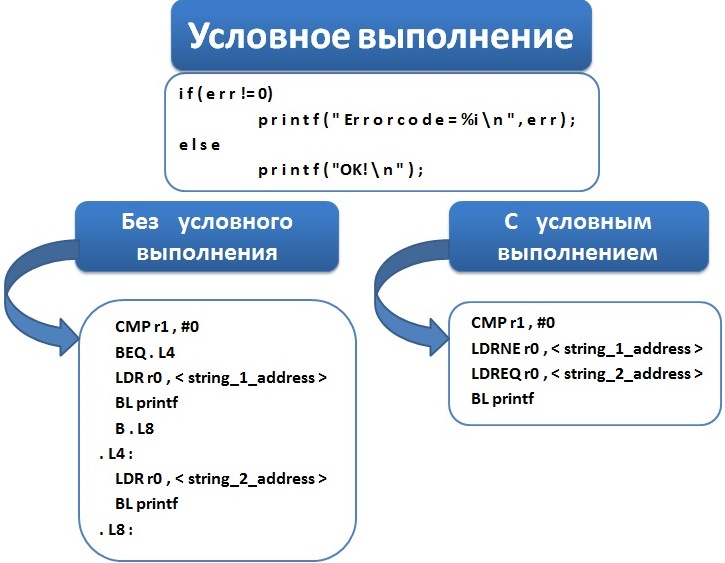
Pic. 5. Compaction
Conditional execution doesn’t offer the opportunity to analyze CFG correctly with any method based on CFG analysis, as static analysis doesn’t allow to find out what specific instructions are to be executed and what instructions are going to be ignored. The instruction flow graph won’t display the real structure of the program to be analyzed either, as many nodes of the graph will be ignored by the processor. In other words, we’ve lost one of the most interesting methods of shell code detection (too many articles were dedicated to this method).
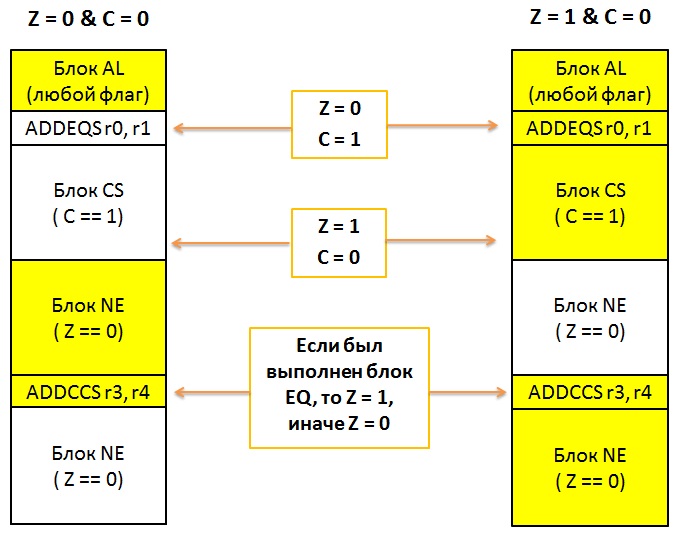
Pic. 6. Example for various instruction flows within one code
This feature makes it more difficult to perform dynamic shell code analysis (emulation). The case is that due to conditional execution of instructions it is possible to redirect instruction execution flow in such a way, that the same code will be able to perform absolutely different actions depending on initial distribution of flag values (e.g. an initial flag distribution may initiate a malicious work load). In order to retrieve initial file distribution, the shell code uses flag register value that had been before the control was passed to the shell code, this is the so-called shell code ‘non-selfcontained’ technique.
How does it happen? Let’s look at the example provided on pic. 6. Here we have the same program that was launched twice but with different initial conditions (to simplify the process we’ll discuss only two flags: ZERO and CARRY). We have an instruction block with ‘AL’ suffix at the beginning of the program. This means that all the instructions will be executed despite the number of flags. Then we can see ADDEQS r0, r1 instruction that will only be executed with ZERO = 1 flag, i.e. in the right emulation only. Besides, this instruction will change flag distribution in the right-hand emulation (thanks to ‘S’ suffix). Now we have two blocks: CS: CARRY = 1, and NE: ZERO = 0. Moreover, ‘NE’ block may affect the values of ‘r3’ and ‘r4’ registers, so that the flags will be changed differently in the subsequent ADDCCS r3, r4 instruction (executed in both emulations). Please pay attention that the same instruction will give out different results with different initial emulation conditions. Besides, this instruction will affect possible subsequent instructions. Thus, a hidden instruction sequence is formed being only activated with conditions which are necessary for the shell code.
Well, ARM shell code is extremely crafty to be detected during one emulating procedure. That’s why it’s recommended to perform emulations with all possible initial conditions (there are 15 of them, as many as conditional suffixes). Besides we don’t know where exactly in traffic the shell code is located, so we need to analyze from each offset. These factors together affect “very negatively” the real time performance of traffic analysis.
Direct addressing to instruction counter
ARM architecture allows to address instruction counter directly. This, of course, makes a malefactor’s life much easier. Even ‘GetPC’ code being often used for x80 shell coding is not obligatory now. As you may remember, this technique allows to get register value for instruction counter without direct address to it. ‘Call label’ call instruction is inserted into the shell code on close offset (inside shell code), with ‘pop bx’ stack register picking instruction executed, because ‘call’ instruction keeps return address on the top of the stack. Thus, typical heuristics for x86 shell codes must be modified: now we will seek Get-UsePC code instead of GetPC code.
Get-UsePC code can be understood as reading of ‘PC’ instruction counter values and subsequent use of this value. In order to calculate the instruction counter value you can address ‘PC’ (‘R15’) register directly; you can also activate the function with ‘BL’ instruction and then use the value of ‘LR’ (‘R14’) register with the return address.
The problem lies in the fact that legitimate programs will definitely use GetPC code: it is necessary to return control from (MOV PC,LR or `LDR PC,#Зvalue_from_stack) function. That’s why in order to separate chaff from grain we should also take into account the value of instruction counter register. I.e. we have to find out which registers implicitly refer to the instruction counter and check where they were applied. E.g. if the register was used in a memory reading instruction, then we can confirm that here we have a decrypter, as the reading will be performed with close offset and, subsequently, from shell code workload. An example of such shell code is given on pic. 7 (this shell code was taken from exploit-db.com).
When a function is activated, the parameters are put to registers
Unlike x86 architecture, where the parameters are transferred to functions through the stack, ARM architecture writes the parameters into ‘R0-R3’ registers. If the number of parameters is greater, then the rest of the parameters are put on the stack, as in x86.
So bye-bye, ROP shell codes! Well, of course not really bye-bye… At least this feature will complicate their coding. ROP shell code activates functions from system libraries in order to make malicious workload out of their parts. It’s rather difficult to use this method due to the fact that shell code patterns must contain initialization of parameters into registers. I.e. we can see that rather rare necessary “parts” will become even rarer. Well, at least somebody’s imagination will now not fly so high.
Being an executable code, the object under inspection has the properties which are specific for various OS’s. Particularly, an executable code has to run with OS or core library activations. So, a detector based on search of specific instruction patterns (including system calls and their number count) was typical for x86. Everything is not like that in ARM, again.
The following sequence of actions takes place in ARM to activate a function: the parameters of the function are put to a general purpose register (R0–R3) and to the stack (if the number of parameters is more than four), then ‘BL’ function is activated (‘BLX’ if the function is written with the use of instructions from another processor mode). In order to make ‘svc’ system call, we should upload the system call number to ‘R7’ register and upload the call parameters to general purpose registers (if these parameters are required for a system call).
That’s why in order to detect this attribute we need to use the technique of abstract instruction execution. What is this technique? The code is executed without saving of register values. The only thing that we are able to monitor is which registers have been initialized with specific values. Thus, we must check whether general purpose registers were initialized (and ‘R7’ register for system calls) before a system call or a function activation. E.g. pic. 7 shows the code with system calls initiated (part of Metasploit shell code).
x86 heritage
ARM inherited some shell code features form x86. Thus, detectors for such features may also be left without any significant modifications and on their favorite warm place. Some static shell code features and dynamic decrypter detectors (shell codes are usually obfuscated) may also be referred to them.
- NOP trace detection.
As a rule, such detectors analyze correct disassembly of instructions from each offset, that is a typical NOP trace attribute. Just one thing: the number of disassembled instructions is only counted for each processor mode separately, because if instructions from different modes are used in NOP trace, then the control may fall on an instruction using a mode that differs form the current processor mode; then the instruction will be interrupted:unexpected instruction. - Return address is located in the specified value range.
Return address in shell codes is overwritten with a value located within the address range of an executable process. The lower limit of the range is defined by the origin of the overwritten buffer. The upper limit is defined asRA˘SL, where ‘RA’ is the return address field address, and ‘SL’ is the length of a malicious executable code; or asBS˘SL, where ‘BS’ is the origin of the stack. This attribute is general for all the tested objects which don’t use address space layout randomization (ASLR). Detection is modified for no platforms under consideration. - Analysis of number of work load readings and unique memory records.
The detected object may be considered a polymorphic shell code, if these parameters exceed the specified threshold, and control flow at least once is passed from the address space over to the address where a record was performed earlier (pic. 1). The number of readings is not counted in terms of the number of instructions (as ARM supports simultaneous load of several registers at once), but the amount of registers loaded by ‘LDM’ instruction (‘LDR’ instruction can read only one register). Also, decrypted shell code workload is written to close address for shell code decryption. The number of records is counted by the number of registers uploaded to memory with ‘STM’ instruction (‘STR’ instruction can write only one register). After the shell code has been decrypted, we need to pass the control to the decrypted workload (pic. 10), i.e. the address to which the record was done earlier.
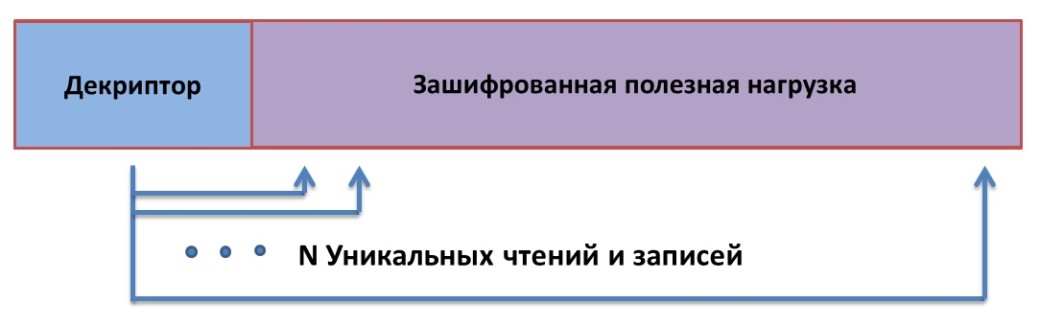
Pic. 9. Decryption of shell code work load

Pic. 10. Passing control to the shell code work load
Conclusions
Summarizing everything said above we can make the following conclusion. In our opinion, ARM processor epoch is living a second life. In the nearest future the necessity to protect such systems will become more and more important. As for shell codes… Having scrutinized the differences between these two platforms we now are able to make the following conclusions. First, these differences have partly modified shell codes; second, they allowed malefactors to implement essentially different obfuscation techniques. All this resulted in the fact that the existing detection methods for x86 in case of ARM either break down or may hardly be applicable (e.g. they run longer, much longer). Taking into account the fact that detection speed is limited drastically, the conclusion is disappointing. On the contrary, the difference between these two platforms allows us to find some features which are only specific for ARM shell codes, and that of course is a positive sign. In other words, the development of ARM shell code detector is crucial and possible.