
Identifying critical data in the code
In my report presented at the summer Offzone conference, I explained how the semgrep engine and custom rules can be used to parse the code of various services and extract important objects from it. The main idea is as follows.
Protection of customer data is the main priority for any AppSec engineer, and it’s imperative to monitor microservices in your product that contain names, addresses, phone numbers, passport data, financial information, logins, passwords, and other sensitive data. This approach makes it possible to focus your information security processes on such microservices (i.e. select those 20% of microservices requiring special attention and gain 80% of benefit).
Imagine a typical situation: your product is connected to the Internet via some API gateway, and all information transmitted there along certain routes can be found in the Swagger file contained in the code of that gateway. Internally, services communicate with each other via GRPC, and all their external methods are stored in proto files. Services that write something to the Postgres database store SQL schemas in the migrations folder. And to be aware what is stored where, you must be able to parse Swagger, proto, and table schemas in some uniform way.
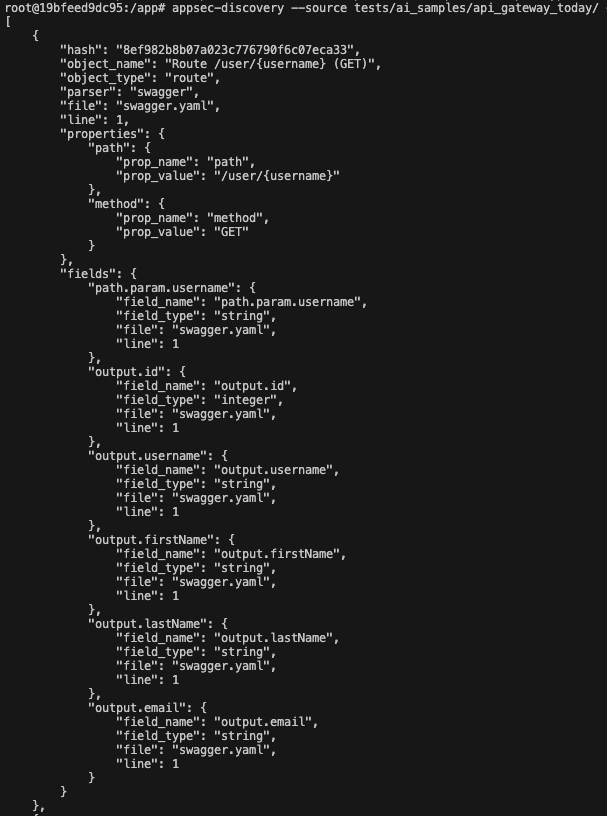
If you add a new field (e.g. snils (personal insurance policy number)) to a user object, it will appear both in Swagger on the gateway, in the proto-contract, and in the service database scheme of the user data owner. If you compare two states of code (i.e. today and yesterday) you’ll see this new field in these diffs.
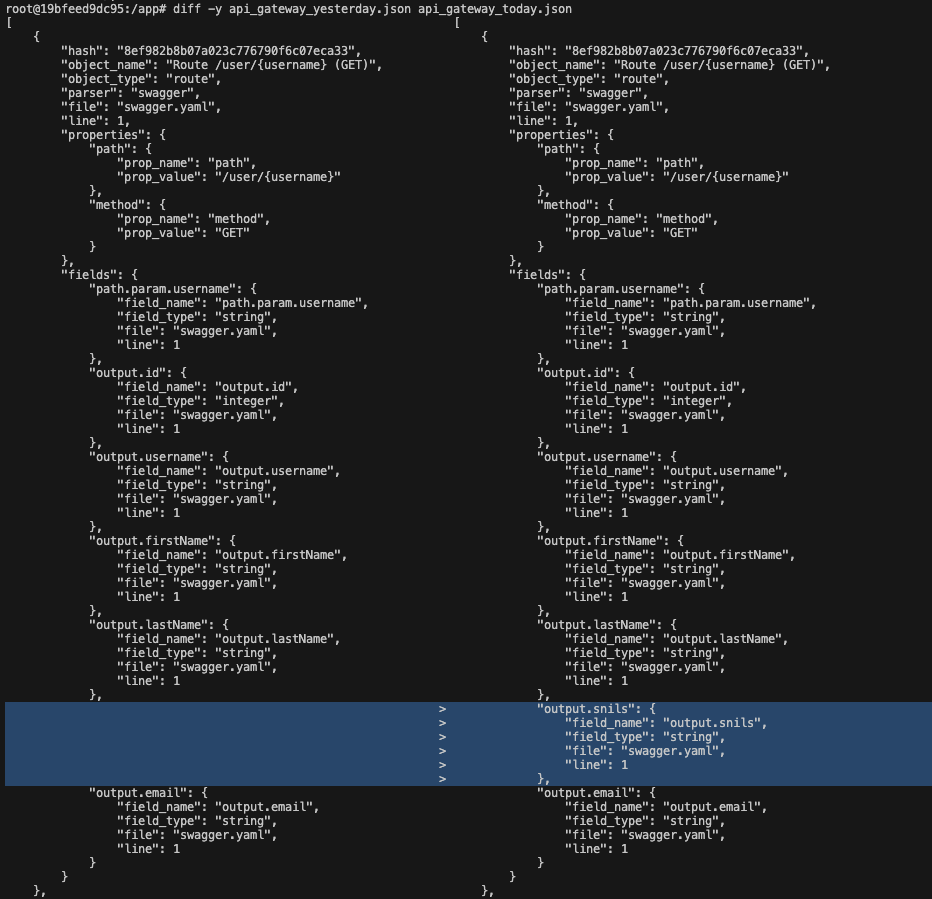
So, now you can extract Swagger and Protobuf from the service code, and a comparison of the service states as of yesterday and today shows which fields have changed.
Scoring on a small scale
An experienced AppSec engineer can immediately oppose: in large products, huge numbers of changes in services occur on a daily basis. Even if you only monitor changes in external contracts (proto, GraphQL, swaggers, and DB schemas), you can still drown in dozens of change notifications. Accordingly, you have to filter the flow somehow.
Since you comprehend the architecture of your product, you know (at least intuitively) what data contained in it must be protected by all means. Let’s try to create a basic set of keywords so that all fields in your contracts (and contracts containing these fields) are scored as critical; while the rest are not. To implement this idea, you have create a basic set of rules to classify fields in contracts by their criticality.
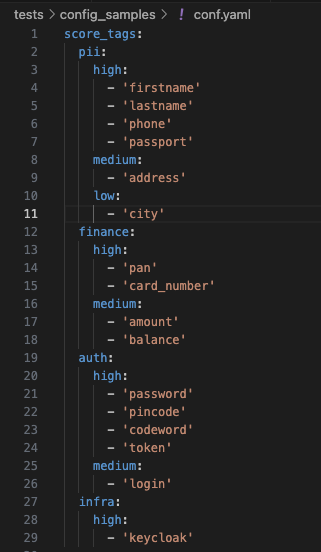
Now some fields in your objects have been assigned certain severity levels and tags determining the data type.
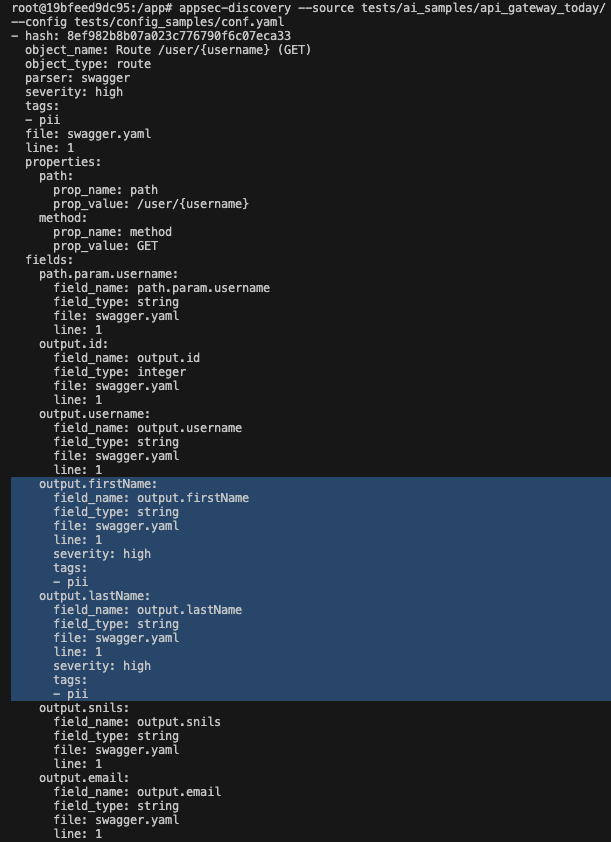
Voila! Now you can use the existing data schemas to understand where you have plenty of critical information, which services require greater attention, and which ones can be left alone for now.
With regards to the flow of changes, now you can react only in situations where critical fields have been added or changed in the schemas (since you don’t really need to know that some user now has a field called “Favorite Movie”). But if the added fields include, let’s say, taxpayer identification number or passport number, this definitely deserves your attention.
Choosing steel brains
The basic rules are in place, but what if a new data type (not covered by the existing rules) appears in your product? The above-discussed examples indicate that it would be great to somehow categorize snils and email that aren’t mentioned in the basic rules.
How to incorporate basic common sense into the logic governing the evaluation of new objects? The task sounds simple: the system should notify you if it finds something suspicious. Such a task seems to be suitable for modern LLMs. Let’s test this hypothesis on the King of all LLM models: His Majesty ChatGPT.
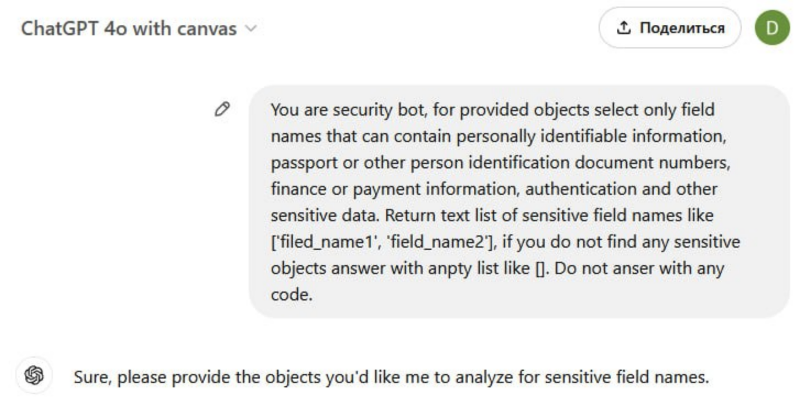

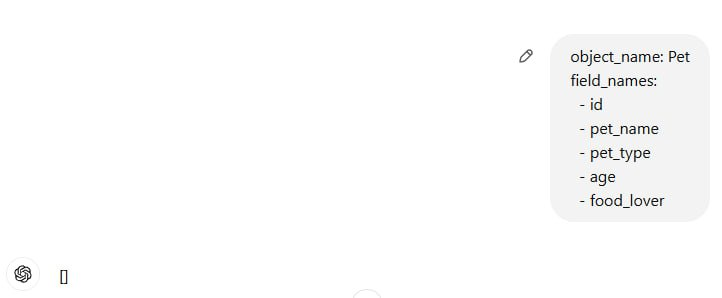
The result is predictably perfect. But a whole range of problems arise: using ChatGPT API costs money; ChatGPT is unavailable in some regions; and, most importantly, transfer of critical data to an external API is totally unacceptable for an IT security specialist. Even if this isn’t about the data per se, but about metadata reflecting the structure of objects and relations between them.
In other words, an on-premise alternative (preferably an open-source one) is required. In this category, top performers include Llama 3.2 by Meta and Phi 3.5 by Microsoft. The easiest way to test the quality of these tools is to visit Huggingface: plenty of original, quantized, and uncensored models are available there.
My experiments showed that two models are optimally (in terms of their size, consumed resources, and logic) suited to solve the above-defined problem: quantized and censored Llama 3.2 on 3B (3 billion tokens) and Llama 3.1 on 8B.
Other models of the same size either have trouble choosing the correct set of fields from the suggested list, or make mistakes with the result format, or don’t fit into local resources.
Using local models
Let’s see how the selected models can be used locally. Popular options for the Python ecosystem include transformers from the above-mentioned Huggingface and llama-cpp-python that represents a wrapper for the C library llama.. The first option performs well when it has access to the GPU, but without it, I didn’t get any results on the CPU of an old Macbook Pro M2. Overall, llama-cpp-python turned out to be the best choice for regular desktop hardware and virtualization: the model loads in seconds, and subsequent responses also take a few seconds, which is an acceptable result for such a task.
Commands calling the model from the code are quite trivial; the system prompt is similar to that used for ChatGPT.
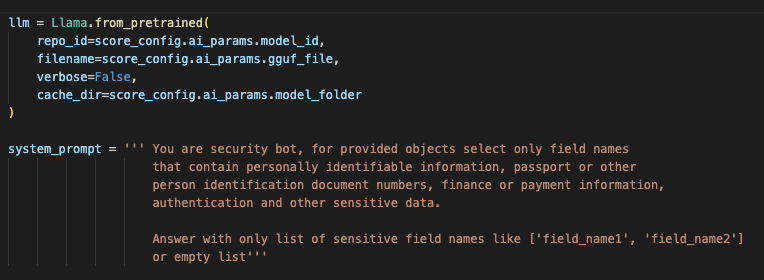
At the first start, the library loads the selected model to the specified cache directory; then this cache can be used in an offline environment.

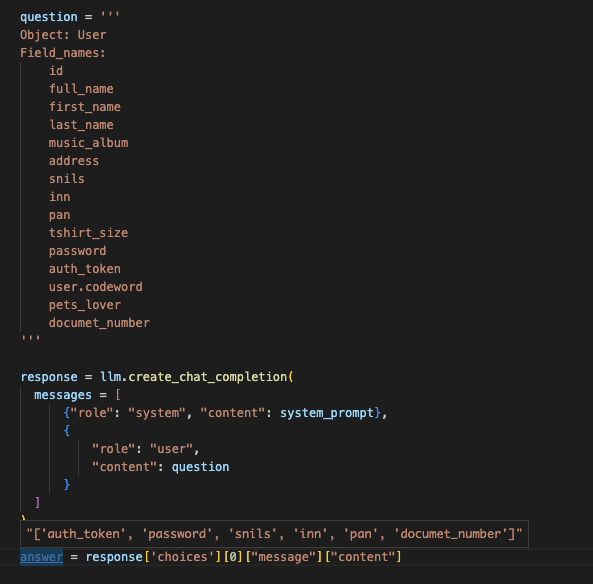
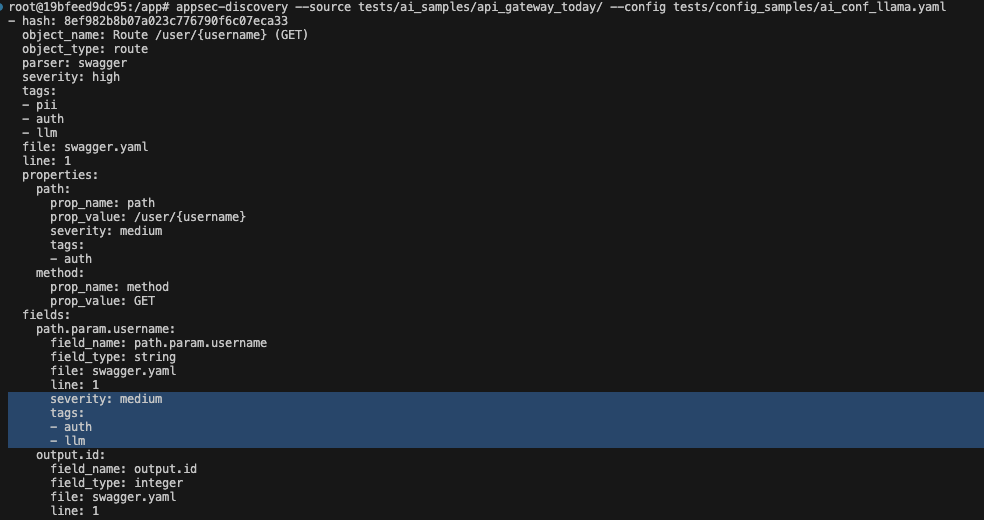
Results obtained with the 3B model are shown below.
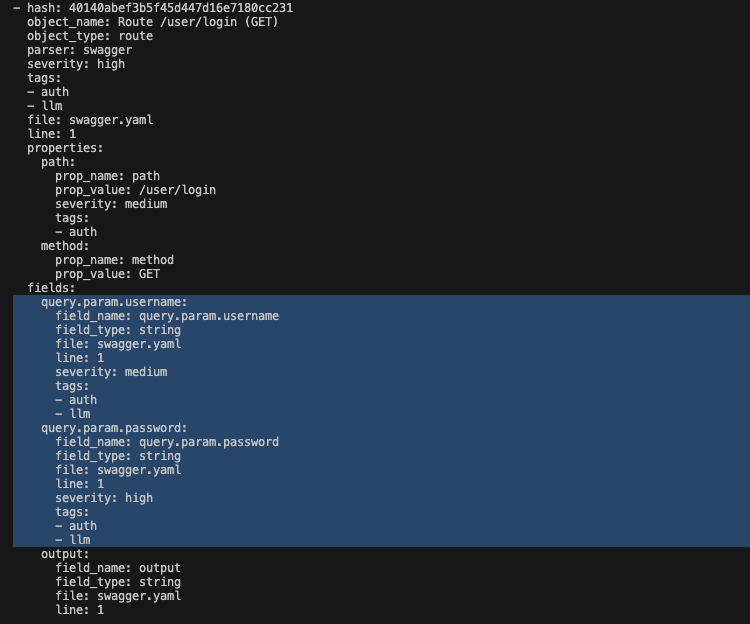
The next screenshot shows results obtained with the 8B model using the same prompt.
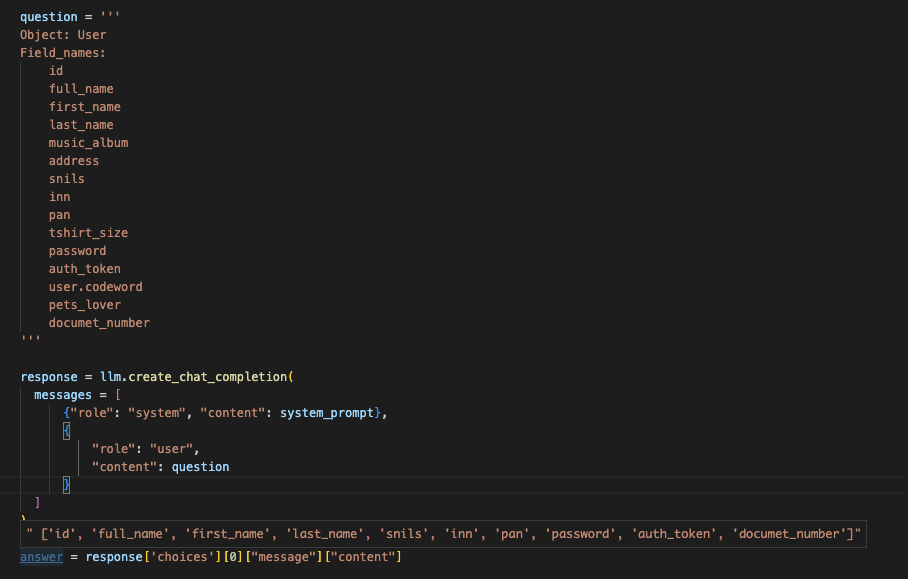
The smaller model returned the result in some 10 seconds, and, as you can see, this result is far from perfection. The larger model was thinking for some 30 seconds and found a larger number of significant fields – although missed codeword and added id, which is obviously unnecessary for this context.
Also, on a large data sample, the response adequacy strongly depends on the number of fields in the request: in an object with a small number of fields, both models can consider a field to be critical, and both of them can mess up if you have branched data structures at the input and output of the object.
Using the trial-and-error method, I found out that the smaller model is optimal in terms of the ratio between result quality and computation time if you make queries for individual fields. You spend just a few seconds on each field and get a stable result in most cases.
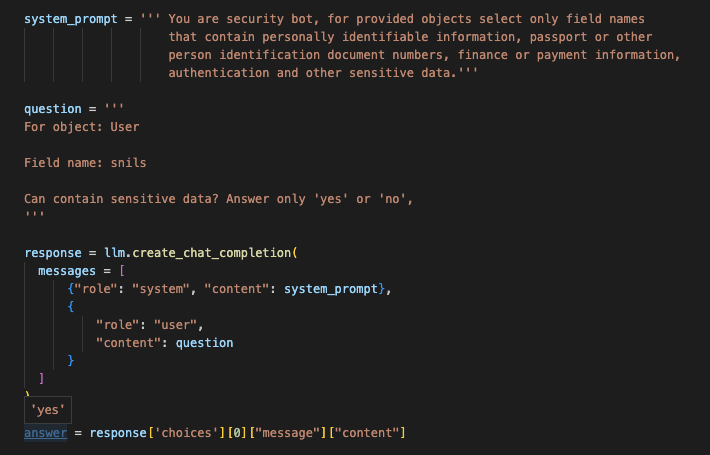
The larger model is comparable to its cloud analogs if you make queries for individual fields, but it spends 15-20 seconds on each request, which is too much for large objects. You have to take into account such aspects as caches, a pool of model objects deployed in memory and warmed up, load distribution throughout it, and hardware suitable for this task. It must be noted that large amounts of memory and GPU provide a dramatic increase in speed, and the response time on larger models drops to a few seconds.
Now you can get critical objects in the scanner output using fairly general requests at the input.
Conclusions
You’ve got a tool that extracts objects from the code based on your predefined set of keywords or based on a general prompt to an LLM model. Of course, it would be great to be able to use this tool in the longer term.
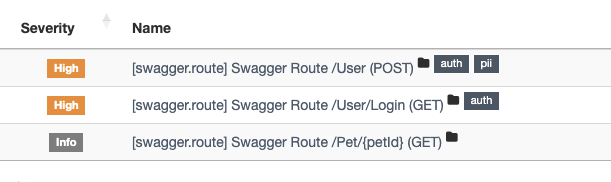
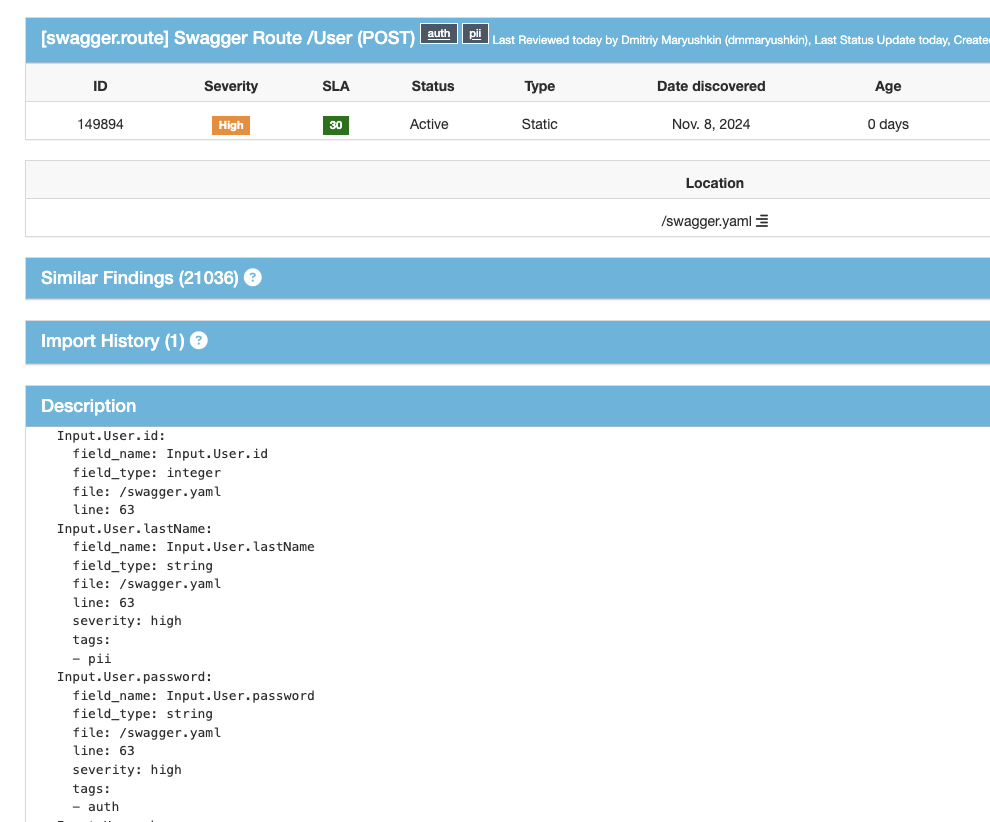
The easiest way to achieve this is to scan the available code base on a regular basis and examine diffs with critical changes. If new critical objects have appeared, you have no choice but to delve into the details.
There is also a more sophisticated way: you run a discovery scan in CI/CD, load the results to SARIF (--output ), and then sent them to DefectDojo. The appearance of new critical objects in the scanner output can be tracked and triaged in the same way as you deal with vulnerabilities.
www
The Appsec Discovery tool used to scan the data shown in the screenshots is available in my GitHub repository.
In the company I work for, we collect the structure of objects, evaluate their severity, load the results to the database in a separate discovery service, and then construct charts and other analytics using Apache Superset in combination with Trino.