
An identification, user detection or, simply, web-tracking, all that means a computation and an installation of a special identificator for each browser visiting a certain site. By and large, initially, it was not designed as a ‘ global evil’ and, as everything else has another ‘ side of a coin’, in other words it was made up to provide a benefit, for example, to allow website owners to distinguish real users from bots, or to give them a possibility to save user’s preferences and use them during the further visits. However, at the same time this option catch promo’s fancy. As you know, cookies are the most popular way to detect users. And they have been being used in advertising since 90s.
Many changes have taken place ever since, in the sphere of technologies a huge step forward have been made and today we can use not only cookies but many other ways for tracking users. The most obvious method is to install an indificator similar to a cookie. Another way is to use the information from the user’s computer, that we, actually, can get from the sent requests of HTTP-headers: address, OS type, time and so on. And, finally, we can distinguish a user upon his habits and behaviour ( the way he moves the cursor, favourite site sections and so on).
Obvious Identificators
This approach is quite obvious, all that we need to do is to place some long-lasting identificator on the user’s side, that we can request during the further visits. Modern browsers allow to make it in a transparent manner for the user. First and foremost, we can use good old cookies. Then, it could be specific features of certain plag-ins, that have similar to cookies software, like, Local Shared Objects in Flash or Isolated Storage in Silverlight. Also we can find some storage mechanisms in HTML5, including localStorage, File and IndexedDB API. Besides, we can save unique markers in cache-resources on local machines or in the cache metadata (Last-Modified, ETag). Furthermore, we can detect a user by his fingerprints that we can get from Origin Bound certificates, generated by the browser for SSL-connections, or, by the data contained in SDCH-dictionaries, or by the information in those dictionaries. In short, there are plenty of possibilities.
Cookies
If we are talking about storing a small amount of information on the user’s side the first thing that pops up in our minds is cookies. A web-server install a unique identificator for each new user and save it in their cookies, so, the client will sent it to the server with each further request. Even though, every modern browser has a convenient interface that allows to deal with cookies, as long as there are a great amount of utilities in the internet to control or bloc them, we still continue to use cookies for user-tracking. The case is that there are not really many people who look through or clean them ( try to remember when did you do it for the last time ). Probably the main reason for such situation is that we just don’t want to delete some necessary cookie, that, for example, is using for an authorisation. Although, most browsers allow to restrict the installations of ‘alien’ cookies, the problem does not disappear, because it is quite common situation for browser to ‘consider’ as ‘native’ ones the cookies that are gotten through HTTP-redirects and other ways while downloading page contents.
Unlike other mechanism that we are going to discuss later, the usage of cookies is transparent for the end user. Moreover, it is not necessary to store an identification in a separate cookie to ‘mark’ a user, it could be simply collected from other cookies or be stored in metadata, like Expiration Time. That is why it is quite difficult to understand whether some certain cookie have been used for tracking or not.
Local Shared Objects
To store data on the client’s side by means of Adobe flash we use LSO mechanism. It is cookie’s analogue in HTTP, however, unlike the last ones it can store not only short fragments of text data which, in its turn, complicates the analysis and check-up of such objects. Until the release of the 10.3 version the flash-cookies’ behaviour has been set up separately from the browser settings, likewise, you needed to go to the Flash settings manager, situated on the macromedia.com site ( by the way, it is still available on the further link (bit.ly/1nieRVb)). Today you can do it right from the control panel. Furthermore, most nowadays browsers provide quite good integration with flash-player, so, during the deleting of cookies and other sites’ datas the LSO will be deleted as well. On the other hand, the interaction is not that good, so the setting up the policy about outside cookies will not always consider the flash’s ones ( here you can find how to turn them off manually (adobe.ly/1svWIot)).
Isolated storage Silverlight
The software platform Silverlight is quite similar to Adobe Flash. So, for example, the mechanism Isolated Storage is the analogue to Local Shared Objects in Adobe. However, unlike Adobe the privacy settings in here are not connected to browser that is why even after deleting all the caches and cookies from a browser, all the data saved in Isolated Storage still will be there. But what is more interesting, the storage is common for all the tabs of a browser ( except those in ‘incognito’ mode), as long as for all the profiles, installed on the one machine. Just like in LSO, from the technical point of view, there is no obstacles to store session identifications. Nonetheless, regarding the fact that you can not influence the mechanism through browser settings, it has not got such an expansion in term of unique identificators storage.

HTML5 and the data storage on the client’s side
HTML5 is a mechanism that allows to store structured information on the client side. Among them we have localStorage, File API and IndexedDB. Despite the differences their purpose is to store random amount of binary data connected to a certain resource. Moreover, unlike HTTP and Flash cookies there is no particular restrictions regarding the size of stored files. In modern browsers the HTML5 storage is situated among other site data. Nevertheless, it is quite difficult to figure out how to control the storage through a browser. Like, for example, to delete the information from the Firefox localStorage the user have to choose “offline website data” or “site preferences” and set up the time interval on “everything”. Another offbeat feature contained in IE is that the data are existing only while the tabs opened at the moment of their saving are alive. Beside everything we have mentioned above we should say that the restrictions applicable to HTTP cookies does not really work with the mechanisms. For example, you can write and read from localStorage through cross domain frames even when the side cookies are turned off.
The randomised objects
Everybody wants browsers work fast and do not lag. That is why it is supposed to store the resources of the visited sites in the local storage ( in order not to request it during the further visits). Although, the first and foremost purpose of the mechanism was not designed as a direct access storage, we can do so. For example, a server could return a JavaScript-doc with a unique identificator inside and install it in the Expires / max-age= headers for the future. That is how the script along with the unique identificator will be stored in the browser’s cache. So, when the operation is completed you can request for it from any web page, just asking for the script download from known URL. Of coarse, the browser is going to ask for the new script version by means of If-Modified-Since header. Anyway, if the server will return the 304 code (Not modified), than cache copy will be working forever. Is there anything else interesting about the cache? Well, there is no concept of ‘ side’ objects like in HTTP-cookies. However, if we turn the randomising off it might influence the productivity greatly. What about auto-detection of smart resources storing certain identificators inside it is quite difficult to make due to the size and complexity of JavaScripts docs existing in web. Сertainly, all the browsers allow users to clean cache manually, however, practically people do it quite rarely, if they do it at all.
ETag and Last-Modified
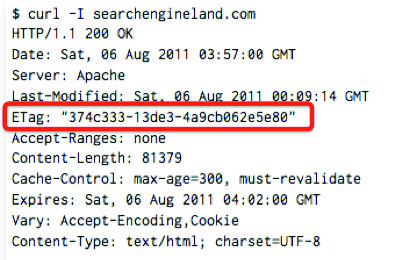
A server should inform somehow a browser that the new version of the document is available in order the randomising works properly. That is why HTTP/1.1 offers two ways to deal with this problem. The first one is based on the date of the last modification, while the other one on the abstract identification known as ETag.
Using ETag, first, a server returns a so called version tag in a header of the reply with the document itself. With further requests to set up URL a client will send through the header If-None-Match this value associated with its local copy to the server. If the version in the header is up-to-date then the server will send the HTTP-code 304 (‘ Not Modified’) and a client will continue to use the randomised version. Otherwise the server will send a new version of the document with a new Etag. This approach are quite similar to the HTTP-cookies – like, the server stores random value on a client to be able to read it later. The other way is to use the Last-Modified header that allow to store at least 32 bits of information in the data string, that further will be sent by a client to the server in the If-Modified-Since header. What is interesting, that most browsers don’t request the correct date format in the date string. The situation here is the same as with the identification through randomised objects, the deleting of cookies and site data does not influenceETag andLast-Modified, you can delete them only by cleaning the caches.
HTML5 AppCache
Application Cache allows to set up which part of a site supposed to be stored and be available even if a user is offline. The mechanism is controlled by manifests which set up the regulations of storing and extracting of the cache elements. Just like traditional randomising mechanism the AppCache also allows to store unique information that depends on user as inside the manifest itself so inside resources that exist for an indefinite amount of time ( in contrast to an ordinary cache which resources are deleted after some time). AppCache occupy an intermediate value between the mechanism of data storing in HTML5 and the common browser’s cache. In some browsers it is cleaned due to deleting of cookies and site data, while in the others only after the deleting of browsing history and all the randomised documents.
SDCH – dictionnaires
SDCH is a compression algorithm designed by Google that is based on the usage of dictionaries provided by the server,they allows to get the highest level of compression rather than Gzip or deflate. The problem is that usually a web-server sends too much repeating information, like, page footers and headers, imbedded JavaScript/ CSS and so on. While using this approach a client get a dictionary file from a server, including rows, that could appear in further replies, like, header… After that the server could simply refer to those elements inside the dictionary, while a client will collect a page based on them by himself. As you understand, we can easily use these dictionaries for storing unique identificators that could be placed as in the dictionary ID, returning to the server by a client in the Avail-Dictionary header, so in the content itself. Further you can use it just like an ordinary browser’s cache.
Other storage mechanisms
These are not all the options available. By means of JavaScript and its ‘colleagues’ it is possible to store and to prompt for unique identifications so they will stay ‘alive’ even after deleting whole browsing history and site data. One of the options is to use window.name or sessionStorage as a storage. Even if a user clean all the cookies and site data but have not closed the tab where was opened a detective site, then the identification token will be received during further opening and the user will be connected again to the already collected information about him. We can track the same behaviour at JS, like, any opened JS-content keep the mode even after a user delete all the site data. Moreover, such JavaScript could not only belong to the displayed site, but also hide in the iframe’ах, web-workers, and so on. For example, the advertisement downloaded in the iframe do not give a damn about the browsing history and site data deleting and continue to use identificator saved in the local JS variable.
Protocols
Besides mechanisms connected to randomising, JS and other plug-ins usage, the modern browsers also have another particular features, that allows to keep and take out the unique identificators.
- Origin Bound Certificates (aka ChannelID) – are the persistent self-signed certificates that identifies a client to server. A separate certificate is created for each new domain, that is being used for connections initiating in future. Also sites could use single external signal to track users without any actions along with, that a client could notice. The cryptographic hash of a certificate could be used as a unique identification as well, given by a client as a part of legitimate SSL-‘handshake’.
- There are two mechanisms in the TLS as well – session identifiers and session tickets that allow clients to resume link-downs connections without ‘full-handshake’. It is possible to do using randomised data. The two mechanisms allow servers to identify requests sent by clients within quite small amount of time.
- Almost all modern browsers use their own inner cache to accelerate the name resolution process ( moreover, in particular cases it allows to cut the risk of DNS rebinding attacks). Such cache could be easily used to store small amount of information. Like, for example, if you have about 16 available IP addresses, it would be enough to have about 8-9 randomised names, to identify any computer in web. However, such approach are restricted by the size of the inner browser’s DNS-cache and, potentially, could provoke conflicts with name resolution regarding DNS provider.
Machine characteristics
All the methods that we have considered are supposed the installation a unique identification that would be send to the server during further requests. However, there is another way to track users based on requests or characteristic changes in terms of a client machine. Separately each received characteristic is just a several bits of information, but if we combine some of them, we can identify any computer in web. Beside the fact that such tracking is far more difficult to recognise as long as to prevent, the technique will allow to identify a user that uses different browsers or private mode.
Browser’s fingerprints
The simplest approach in terms of tracking is to build an identification by combining different available parameters in the browser’s environment, that, actually, does not have any value separately, however, together they create a remarkable features for each machine:
- User-agent. Hand out a browser’s version, an OS version and some installed add-ons. In cases when there is no User-agent or you would like to check its ‘truthfulness’ we can determine the browser’s version by checking certain implemented or changed features between releases.
- Clock rate. In case if a system does not synchronise its clocks with the external time server than, sooner or later, they start to go wrong which is lead to a unique difference between the real time and the system time that could be measured within the accuracy of microsecond by means of JavaScript. Furthermore, even during the synchronisation with NTP – server there will be certain warps that could be detected.
- The information about CPU or GPU we can get as directly ( through GL_RENDERER), so through benchmarks and tests, implemented by means of JavaScript
- The display resolution and the window size of a browser ( including the parameters of the second display in case of multidisplay system).
- The list of installed fonts that have been downloaded, for example, with getComputedStyle API.
- The list of all installed plug-ins, ActiveX-controllers, Browser Helper Objects, including their versions. We can get them using navigator.plugins[] ( certain plat-ins could be tracked in HTTP-headers).
- The information about the installed extensions and other software. The extensions, like, advertisement blockers, implement some changes in browsable pages, you can determine these extensions and their settings due to these changes.
Web – fingerprints
There is another row of features in the architecture of the local net and the net-protocols’ settings. These features will be common for all browsers, installed on the client’s machine, they can not be hidden even with privacy settings or certain security utilities. Here the list of them:
- The external IP-address. This vector is especially interesting for IPv6, because last octets could be gotten from device’s MAC-address in certain cases and that is why they are stored even during the connection to different networks.
- Port numbers for outgoing TCP/IP-connections ( for most OS they are usually choose sequentially).
- Local IP-address for users on NAT or HTTP-proxy. Along with an external IP allows to identify the most of clients
- The information about proxy servers that a client is using can be found in HTTP headers (
X-Forwarded-For). In combination with the real client address that we can get using several ways by passing proxy, also allows to identify a user.
Behavior analysis and habits
Another way is to check characteristics that are connected not to PC, but, more likely, to a final user, such as local settings and behaviour. This method also allows to identify clients among different browser’s sessions, profiles and in case of private mode. So, we can draw conclusions basing on further parameters, that are always available for explorations:
- A preferable language, default encoding and time zone ( we can find all these features in HTTP-headers as well as in JavaScript).
- The cache data of a client and his browsing history. The cache elements could be found using time attacks, a tracking can find a long-lasting cache elements relative to popular resources, simply by measuring the time of downloading ( and just notice the transition if the time overpass the time of downloading from the local cache. Also we can get URL files from the browsing history, however, this attack is urge for an interaction with a user in terms of modern browsers.
- Mouse gestures, the frequency and duration of keystrokes, the accelerometer data – all these parameters are unique for each user.
- Any changes in terms of standard site fonts and their sizes, zoom level or usage of special possibilities, like, text colour or size.
- The condition of certain browser features, setting up by a client, like, the block of external cookies, DNS – prefetching, pop-up blocking, flash security adjustments and so on ( the irony of it is that the users that change their default settings as a matter of fact make it far more recognisable in terms of identification).
By and large, these are only the obvious variants that are not hard to plumb. If we ‘dig’ a little further – we can find out more.
Conclusion
As you can see, practically, there are great amount of different ways to track users. Some of them are the result of the implementation defects or gaps and, theoretically, can be fixed, the other ones are quite impossible to prevent without a full changing of the work principles of the computer networks, web applications, browsers. Generally, we can counter work against some techniques, like, to clean caches, cookies and other places where identificators can be stored. However, others work absolutely imperceptible for a user, and it is impossible to protect yourself from them. That is why, the most important thing to remember is that when you are ‘travelling’ in the web, all your shuffles could be tracked.