
Four-cycle engine
How to write fast rules? Let’s have a closer look at YARA and see how this scanner works. Each scan can be represented as a sequence of four cycles. Take, for instance, the following sample YARA rule:
// Imported modulesimport "math"rule example_php_webshell_rule{ // Metadata meta: description = "Example php webshell rule" // Strings strings: $php_tag = "<?php" $input1 = "GET" $input2 = "POST" $payload = /assert[t ]{0,100}(/ // Conditions condition: filesize < 20KB and $php_tag and $payload and any of ( $input* ) and math.entropy(500, filesize-500) >= 5}Let’s examine each ‘cycle’ in more detail.
Cycle 1. Writing a rule or taking it from publics
This task you have to perform on your own and manually. YARA searches for substrings using the Aho-Corasick algorithm. The substrings are called “atoms”. The maximum length of an atom is four bytes.
Below are some examples of atoms:
/abc.*cde/This regexp contains two atoms: abc and cde. Each atom is unique and doesn’t contain duplicate characters. Since they have the same length of 3 bytes, YARA will use the first atom: abc.
/(one|two)three/The following atoms are available in the above example: one, two, thre, and hree. In theory, you can search for thre or hree either separately or for one and two. But what will YARA do?
It will pick the most unique atom, thre, since this will result in fewer matches than one and two (because they are shorter). Additionally, it doesn’t contain duplicate e characters (as in hree). YARA is optimized to select best atoms from each string. Now let’s take a look at opcodes:
{ 00 00 00 00 [1-4] 01 02 03 04 }In this case, YARA will use the 01 atom because 00 is too widespread.
{ 01 02 [1-4] 01 02 03 04 }The 01 atom is preferred over the 01 atom because it’s longer.
Important: strings must contain ‘good’ atoms. Below are examples of ‘bad’ strings containing either too short or nonunique atoms:
{00 00 00 00 [1-2] FF FF [1-2] 00 00 00 00}{AB [1-2] 03 21 [1-2] 01 02}/a.*b//a(c|d)/The worst strings are those that don’t contain atoms at all (see below):
/w.*d//[0-9]+n/Detection rules that use regular expressions without explicit atoms are ineffective since it takes a while to scan the entire system and involves high CPU loads
The sample rule uses the following atoms:
-
<;?ph -
GET; -
POST; -
sser(fromassert).
Atoms are formed from strings contained in the rule; then YARA searches for them when it scans files. If an atom is found, then the entire string is checked.
Cycle 2. Aho-Corasick (automaton) algorithm
When you launch a rule, YARA starts searching for a substring. Cycles 2-4 are executed for all files. YARA searches each file for the four atoms specified in the sample rule using a prefix tree called Aho-Corasick automaton. The same principle is used in grep. Any matches are passed to the bytecode engine.
Cycle 3. Bytecode engine
Imagine that a match for sser was found during the scan. If so, in the next step, YARA will check whether the prefix a is before sser and the postfix t, after it. Next, the regular expression [ is checked. Such optimization enables YARA to avoid complex computations (in this case, regular expressions) and select unique substrings for detailed examination.
Cycle 4. Conditions
Once all pattern comparisons are completed, the conditions come into play. They are tested using short-circuit evaluation also known as McCarthy evaluation.
McCarthy evaluation is based on the following optimization principle: a second logical operator is evaluated only if the first logical operator isn’t sufficient to determine the expression value.
The sample rule contains the following conditions:
// Conditions condition: filesize < 20KB and $php_tag and $payload and any of ( $input* ) and math.entropy(500, filesize-500) >= 5If the size of the scanned file is, let’s say, 25 KB, then the value of the entire condition below will be FALSE since the first condition in the rule limits the file size to 20KB. It’s simple: conditions are evaluated from left to right. If the first condition is FALSE, then all subsequent evaluations won’t be performed.
// Slow conditionmath.entropy(0, filesize) > 7.0 and uint16(0) == 0x5A4D// Optimized conditionuint16(0) == 0x5A4D and math.entropy(0, filesize) > 7.0Be careful when you use for in a condition:
condition: for all i in (1..filesize) : ( anything )For large files, the anything operation can take a very long time to complete. Let’s slightly optimize the rule by adding the PE check condition:
strings: $mz = "MZ"condition: $mz at 0 and for all i in (1..filesize) : (anything )It’s already better, but still not perfect. The rule will skip regular files, but large PE files still will be scanned, which requires a long time. Let’s add a limitation on size:
$mz at 0 and filesize < 100KB and for all i in (1..filesize) : (anything )Voila! You limit the number of iterations by adding a limit on the file size: filesize < .
Now let’s go back to the conditions set in the sample rule:
// Conditions condition: filesize < 20KB and $php_tag and $payload and any of ( $input* ) and math.entropy(500, filesize-500) >= 5Thanks to the short-circuit evaluation, math. (entropy computation is very CPU-intensive) will only be checked if the four conditions evaluated prior to it are met. If all the conditions are met, a match is reported. Then the program proceeds to the next file and scans it starting with the second cycle.
Imported modules
Let’s find out what exactly is slowing down the sample rule.
As you are likely aware, YARA has special modules (both built-in and created by users (starting from version 3.0)) that can be used to analyze PE and ELF files. Also, there are modules for interaction with ZIP archives and radare2 disassembler. Too bad, they aren’t as efficient as it seems at first glance. Let’s test two identical rules. The first one uses the pe module; while the second one, the magic bytes MZ hardcoded in the form of opcodes.
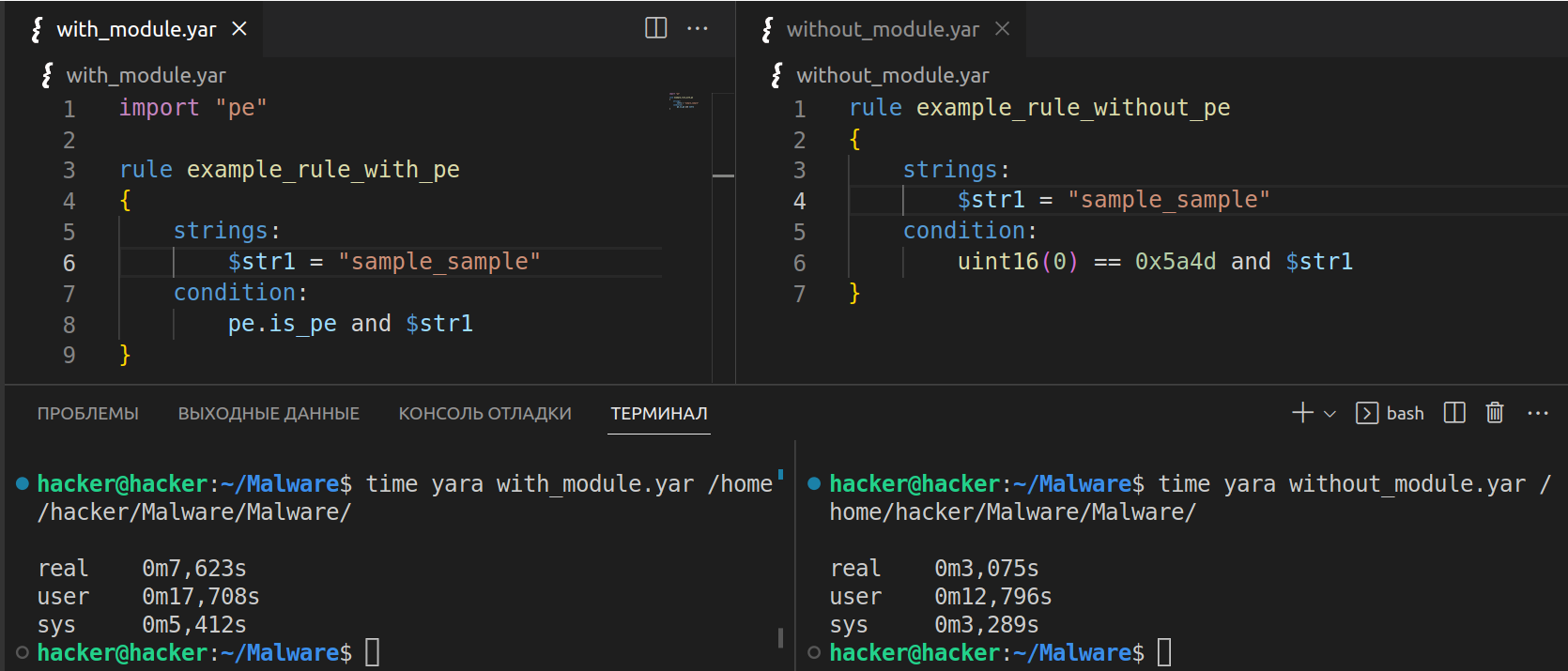
A directory 10 GB in size was scanned. As can be seen from the test results, modules increase the scan time due to additional calculations. In this particular case, it’s better to perform the check using the hardcoded magic opcodes.
Metadata
All information contained in the metadata section is read by the YARA engine and stored in RAM. You can easily verify this by adding 100,000 hashes to a rule and checking the RAM usage by YARA before and after the scan. Of course, there is no reason to permanently remove metadata from rules, but if the host you are scanning is low on memory, you can remove some unnecessary sections of the rule right before the scan.
To summarize the optimization rules.
- Look for good atoms: the more unique letters they contain, the better;
- Don’t use bad regular expressions;
- Don’t overplay with complex loops;
- If you can do without a module, then don’t import it (e.g. magic for a PE file);
- Set conditions in the correct order; and
- If you perform a scan using multiple rules, remove metadata.
Additional tools
In addition to the official YARA binary, you can use EDR/XDR solutions and scanners (e.g. Loki Scanner). EDR/XDR make it possible to scan the entire network infrastructure at once; while yara. is limited to the PC it’s running on.
Velociraptor
Let’s examine the scan algorithm using the open-source Velociraptor EDR as an example.
Go to the Hunt Manager section.
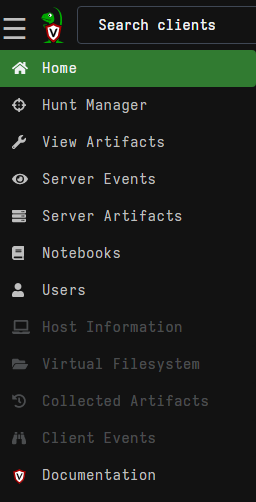
Create a new hunt and select the Windows. option on the Select tab to scan the file system.
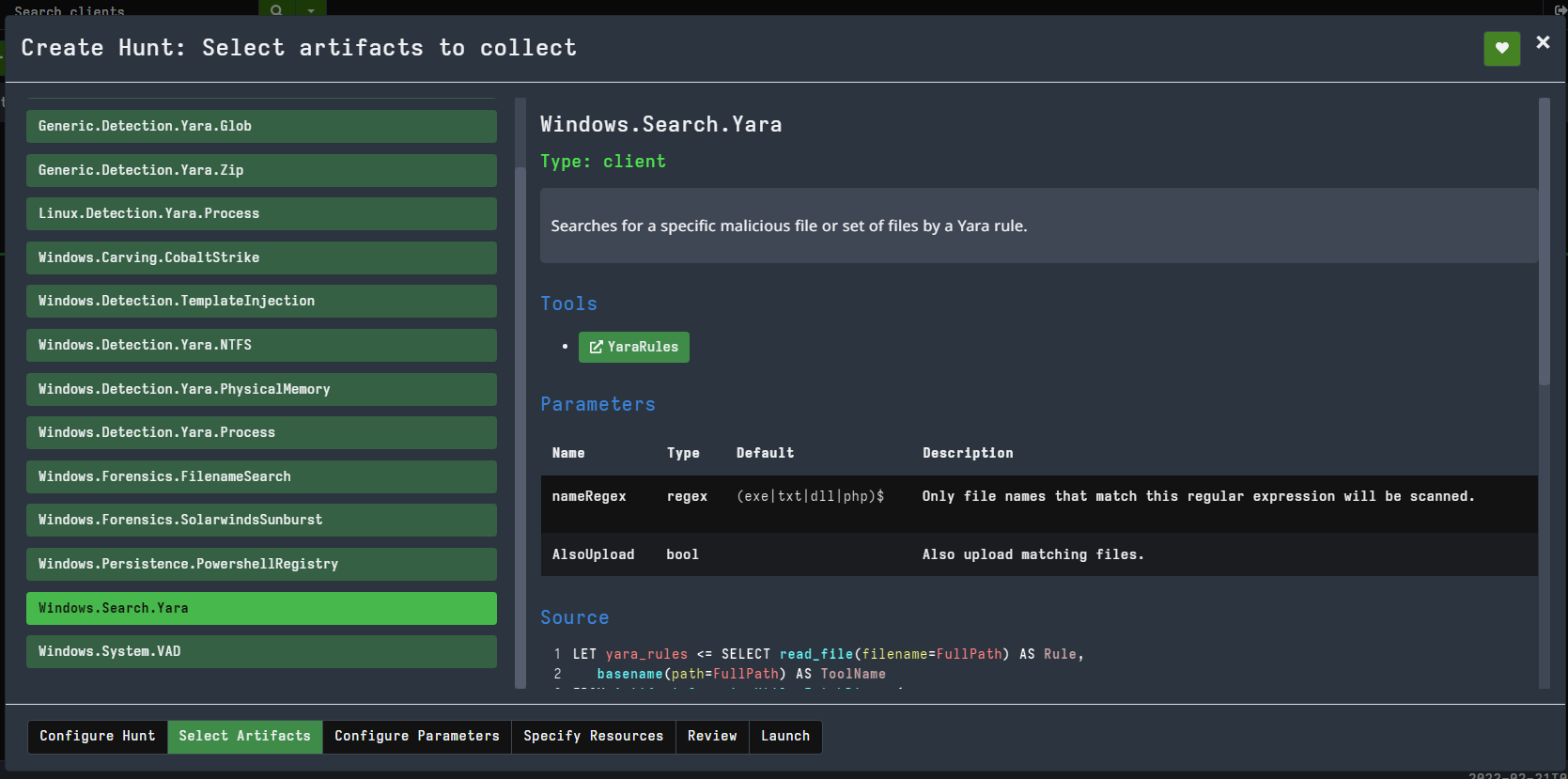
On the Configure tab, either write your rule in the YaraRule field or upload it as a file using the YaraUrl field.
After configuring all the required fields, open the Launch tab, and your hunt will be queued for execution. If you want to run a scan immediately after creating a hunt, open the Configure tab and check the Start box.
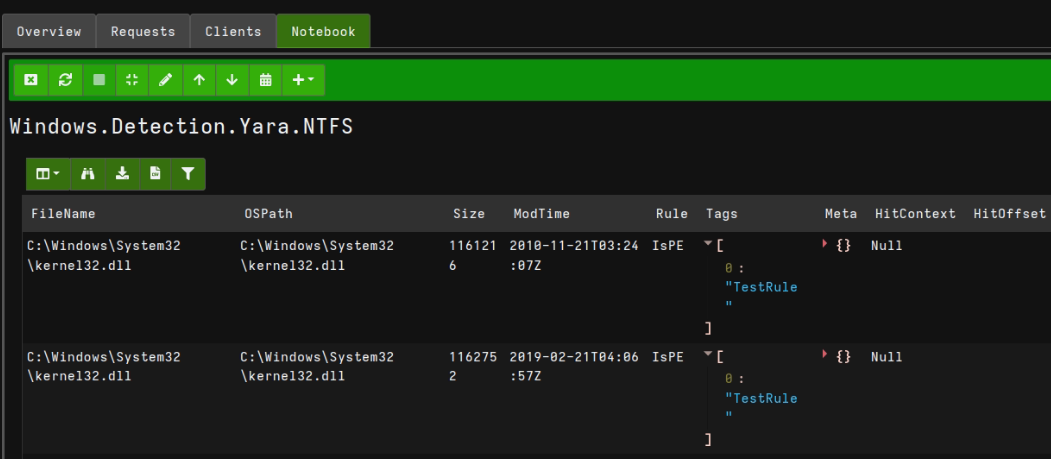
When the scan is completed, you’ll see successful detections inside your hunt on the Notebook tab.
Loki Scanner
Loki Scanner is an open-source console utility that can perform scans using YARA or IOC (Indicator of Compromise) rules.
To add your rules, go to the loki folder; once the rules are added, you can open the CLI (cmd/terminal) and run a scan.
The main arguments are as follows:
-
-p– directory to be scanned;path -
-s– maximum file size in kilobytes (5 MB by default);kilobyte -
--onlyrelevant– only rule triggers to be displayed in the console; and -
--allhds– scan all logical volumes (Windows only).
Attribution in YARA
In simple terms, malware attribution is a way to identify the family or APT group a specific piece of malware belongs to. Attribution for a company isn’t an easy job: it requires a separate department equipped with powerful servers (since the detection rule for attributing a specific sample will be huge).
The yarGen tool can be used for attribution. It creates a general rule for all files. Overall, its operation algorithm is as follows:
- You take several malware samples belonging to the same family;
- You launch yarGen and specify the folder containing your samples; and
- YarGen searches for common strings and/or opcodes and generates on their basis a general attribution YARA rule.
Note that the resulting rule is far from perfection and requires refinement.
Alternatively, you can generate a set of hashes of sections (resources) of threats known to you. To do this, you have to create a YARA rule that contains hashes of all sections that are of interest to you. Why not hashes of sample? Because if you add a couple of bytes to the end of a file, your hash will change; while with sections, this trick is more difficult to perform.
You can also attribute MITRE subtechniques (this option is mentioned just as an example; in reality, it won’t help unless you are going to create your own attribution platform). For instance, there is a rule that attributes the MITRE subtechnique T1552.004.
In my opinion, YARA alone isn’t sufficient for attribution; it’s better to use it in combination with ssdeep.
What else besides YARA?
YARA-X is an official YARA fork rewritten in the Rust language. The project is supposed to increase the scanning speed by optimizing the memory available in this programming language. I believe that it has good prospects: if you look at RustScan (an unofficial Nmap fork), you’ll notice a significant increase in network scanning speed.