
ping
The ping command is familiar to almost everyone, even those with no networking background. It sends ICMP Echo Requests to a remote host, which is expected to respond with ICMP Echo Replies.
But there’s a reason this protocol is called the Internet Control Message Protocol. Its role isn’t limited to diagnostics, and even its diagnostic features go far beyond a simple “did it reply or not.”
What Can Ping Tell You?
Often, if the destination host is unreachable, ping really will return only a request and nothing more. While a successful reply always comes from the destination host itself, delivery error messages come from intermediate routers. Per the standard (https://tools.ietf.org/html/rfc792), intermediate routers may, but are not required to, notify the sender. Frequently they don’t—due to performance considerations—and there’s nothing to fault them for.
But if you do get a reply from an intermediate router, it’s usually informative. For example, the destination message should only be sent when the destination is on the same local network as the router and isn’t responding. The easiest way to see this error is to ping a known-nonexistent address on your own network—for instance, if your network is 192.168.0.0/24 and there’s no 192.168.0.200 in it, run ping .
Such a response can only come from the last router on the path to the host.
By contrast, network means that some node along the route has no route to the specified network. This error can occur anywhere along the path, so pay attention to which device is sending it.
Most of the time, the issue is on your end: your routing settings got wiped, or the host didn’t receive a route from the DHCP server. But this kind of reply can also come from an intermediate router:
From 192.0.2.100 icmp_seq=1 Destination Net Unreachable
If you’re seeing something like this, something has gone seriously wrong. If the host is reachable from other networks, it’s quite possible your provider has a BGP configuration issue. I’ve seen at least once a major provider mistakenly filter prefixes from a range they believed was reserved for future use, even though IANA had already handed it over to RIPE NCC six months earlier and many organizations were already using addresses from it.
www
If you don’t want to end up like that provider, use an automatically updated list of bogon (unallocated/reserved) prefixes, such as the Cymru Bogon Reference.
ICMP error messages of the “destination host/net prohibited” class indicate that a packet was dropped by a firewall rule. However, there’s no requirement to reply in that specific way—or to reply at all. For example, on Linux, rules like iptables return destination by default unless you explicitly set --reject-with, and you can specify any type there, even icmp-net-unreachable.
But that only covers a basic ping with no options. Some issues are easier to uncover using additional flags.
Diagnosing MTU Issues
VPN users may sometimes find that certain resources are unreachable over the tunnel, even though those same resources work perfectly from the same network without it.
A common cause of these issues is a misconfigured destination network, which stops packets from passing through the tunnel. Since the MTU (Maximum Transmission Unit) for tunnels is smaller than the Internet’s standard 1500 bytes, reliable connections require working Path MTU Discovery (PMTUD). Unfortunately, PMTUD doesn’t always work, and the easiest way to break it is to block ICMP “so that nobody can ping us.”
Such pathological cases among network administrators are rare; unfortunately, broken PMTU is common.
You can detect this by setting the packet size with the -s option: ping . If a standard ping with a 64-byte packet works, but ping suddenly stops working at some larger size (e.g., -s ), congratulations—you’ve found the issue. Ask the admin to enable MSS clamping, or enable it yourself if you are the admin.
Detecting Deep Packet Inspection
Many DPI solutions don’t actually look that deep; they just search for fixed strings in packets. In some cases, you can detect the presence of such DPI on the path with a single ping. On Linux, the –pattern option helps with this. The downside is you’ll have to manually encode the suspicious string in hex, but if installing a packet generator isn’t an option, it can still be useful.
TTL exceeded
Another error you’ll only encounter in practice with a special option is Time . The Time To Live field in IPv4 packets (Hop Limit in IPv6) is capped at 255, but the Internet is a small‑world network, and the average path is well under a tenth of that maximum. The original purpose of TTL was to prevent packets from looping endlessly in the event of a routing loop, but modern protocols are designed to prevent loops. Still, nothing stops you from setting a TTL that’s intentionally shorter than the expected path length:
$ ping -t1 9.9.9.9
PING 9.9.9.9 (9.9.9.9) 56(84) bytes of data.
From 10.91.19.1 icmp_seq=1 Time to live exceeded
traceroute
That’s exactly how the traceroute command works: it sends packets with TTL=1, then TTL=2, and so on, waiting for ICMP Time Exceeded replies from each intermediate hop.
At first glance, traceroute seems like as simple a tool as ping. In reality, its output contains more information than meets the eye. At the same time, it can surface phantom issues that don’t exist, while real problems may not show up at all.
Latency
Both the standard traceroute command and tools like MTR are popular for finding network bottlenecks. MTR shows latency statistics for each hop along the path.
However, interpreting this data isn’t that straightforward. Suppose you see 20 ms on the first hop and 950 ms on the second. Don’t rush to celebrate that you’ve found the bottleneck or blame that network’s admins. The latency of ICMP Time Exceeded (TTL exceeded) replies may have nothing to do with actual packet forwarding delays.
In our scenario, 950 milliseconds is simply the time from sending the packet to receiving the ICMP reply. We don’t know how long it took the test packet to reach the destination, or how long the reply took to return. Nor do we know the processing time on the other end—the interval between receiving the packet and sending the response.
It’s a serious mistake to assume this latency is close to zero. First, packet forwarding is often handled by the hardware switching fabric, while the control-plane OS runs on a relatively modest CPU. Since ICMP messages are always generated in software, that path is much slower. Even in pure software implementations, tasks like replying to pings and sending ICMP Time Exceeded are far lower priority than packet forwarding/routing.
So a spike in latency at a hop in traceroute or MTR output, by itself, doesn’t mean anything. But if all subsequent hops have latencies over 950 milliseconds, then you’ve got a real reason to escalate to the admins.
Asymmetric Routing, Load Balancing, and MPLS
It’s just as wrong to assume that return traffic follows the same path you see in traceroute. For transit routers—as opposed to customer-premises gear—asymmetric routing is common, even inevitable.
If provider A’s network is connected to networks B and C over links with the same bandwidth and quality, it’s natural to spread outbound traffic across both. However, even if A’s admins prefer to send most traffic via B, they have very little control over inbound traffic. You can make route advertisements toward C less attractive, but even then there’s no guarantee that customers of network B apply the same policy. It’s entirely possible they actually prefer C.
Suppose network C is actually the one misbehaving. Would traceroute show that? Obviously not, because TTL expiration always occurs on the forward path, not on the return path. There’s no way to see the complete network graph.
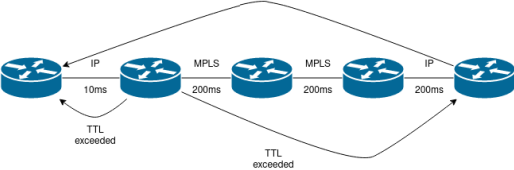
MPLS makes things even more interesting. Because MPLS frames encapsulate entire IP packets, and to the networks at the ends of an LSP it looks like a direct physical link, a large portion of the transit network’s internal structure becomes invisible.
This makes troubleshooting harder not only for users but for providers as well, so operators sometimes use MPLS ICMP tunneling to produce proper replies. However, because the IP packets are sourced by the egress router of the MPLS LSP (no IP processing happens before that point), the path will appear as a series of hosts with zero latency between them.
whois
Say you’ve found a troublesome network via ping or traceroute, or you’ve spotted attackers’ IP addresses in your logs. How do you figure out who to contact about it? That’s where whois helps.
Most people use the whois command to look up domain information (whois ). In fact, RIR databases (Regional Internet Registries — RIPE NCC, ARIN, etc.) contain many more types of objects.
Each allocated resource—whether an autonomous system number or a network address—has a record in the database that tells you who it’s assigned to.
For example, say you want to complain that the authors of “Hacker” are teaching young people the wrong things. You can resolve xakep.ru and run whois . But you suspect the info about the IP itself doesn’t match the hosting provider’s network details. No problem—whois also accepts network ranges:
$ [[..
%
%
inetnum: 178.248.232.0 – 178.248.239.255
netname: RU-QRATOR-20100512
country: RU
org: ORG-LA267-RIPE
admin-c: QL-RIPE
tech-c: QL-RIPE
status: ALLOCATED PA
remarks: QRATOR filtering network
Here we’re shown the abuse contact right away, but if it’s missing you can always dig deeper and look up the WHOIS for any field. For example, whois . By policy, every organization is supposed to have an abuse contact.
You can also retrieve information about autonomous systems from there. Just prefix the number with AS. For example, who owns autonomous system 6939?
$ [[
aut-num: AS6939
as-name: HURRICANE
descr: Hurricane Electric
How you handle people who spam you or brute-force your services is up to you, but in many cases emailing the hosting provider’s abuse contact won’t hurt. Most hosts and ISPs don’t want offenders on their networks, so if you have evidence, there’s a non-zero chance the attacker’s server will be suspended.
Looking glass
Many providers offer looking glass services that let you view diagnostic information from their routers.
They’re accessible via a web interface, and sometimes over Telnet/SSH as well.
Unfortunately, there’s no universal way to find it, and providers rarely list these addresses on their websites. Still, the term is so standard that searching for “$provider looking glass” in any search engine will usually get you there. For example, https:// leads to http://.
Most of them let you run ping and traceroute, while the more full‑featured ones also provide BGP routing information and let you choose routers from different regions.
Conclusion
People are constantly building new and useful tools, but you can always start troubleshooting with the old, time‑tested ones that ship with every system — they may well be all you need.