
We’ll continue exploring what the Stable Diffusion XL generative model can do, which I’ve written about before. In the previous article, we covered installing the model on a computer, generated a few photorealistic images, ran into the notorious hand-and-finger problem common to modern neural nets, and tried to fix it.
We’ll keep using Fooocus for now. However, this is the last article where I’ll be working with it. Next time, we’ll switch to a more advanced setup—AUTOMATIC1111.
Latest Generative AI News
Generative neural networks are advancing at the speed of thought. No sooner had the previous article come out than a flood of news started pouring in.
Just like that, the Fooocus developers release Stable Diffusion WebUI Forge, their own optimized fork of the hugely popular AUTOMATIC1111. The new build follows the Fooocus tradition: it works out of the box and doesn’t require hacky manual tweaking, unlike the original.
Second—Stability AI, the creators of Stable Diffusion, have released a preview build of the next-generation model, Stable Cascade, which you can try online, or install on your own computer via this GitHub link.
Third — ByteDance, the company behind TikTok, has released SDXL-Lightning, which can generate images in fractions of a second—faster than SDXL Turbo and with higher quality. For example, the image below was produced in eight seconds at 2024×2024; at SDXL’s standard 1024×1024, images are generated in under a second. You can try the base model on Hugging Face, but it’s better to download the dreamshaperXL_lightningDPMSDE model from Civitai and run it locally (be sure to read the instructions carefully—this is important).

While I was working on this article, an unexpected bit of news landed: Stability AI has released Stable Diffusion 3, currently available only as a developer preview.
The new Stable Diffusion release—though it’s unclear how it maps to Stable Cascade—comes with big promises that read almost word-for-word like the Midjourney V6 press release. Early samples look impressive, but they’re demos, after all.
Differences between presets
Last time we generated photorealistic images by launching Fooocus with run_realistic., but Stable Diffusion isn’t limited to photos. If you start the model with run., you’ll automatically switch to more general-purpose settings. The negative prompt will no longer include terms that block artistic styles, and the photo‑realism LoRA will be removed from the list of active LoRAs.
info
LoRA (Low-Rank Adaptation) are lightweight adapter modules that augment a base model.
When you launch a file, Fooocus loads settings from the matching preset (stored in Fooocus\). Therefore, use the appropriate launch command based on the type of images you intend to generate.
Since we’re already talking about presets, here’s the difference between the photorealistic (run_realistic.) and the default (run.) configurations:
In the photorealistic preset, the base model is realisticStockPhoto_v10, the LoRA is SDXL_FILM_PHOTOGRAPHY_STYLE_BetaV0.4, the negative keywords are: unrealistic, saturated, high contrast, big nose, painting, drawing, sketch, cartoon, anime, manga, render, CG, 3d, watermark, signature, label, and the default enabled styles are the dynamic Fooocus V2 style, as well as Fooocus Photograph and Fooocus Negative.
In the main preset launched with run., the settings are different. The authors chose juggernautXL_version6Rundiffusion as the base model (a solid general-purpose model), and the LoRA sd_xl_offset_example-lora_1. (by default it boosts contrast; with higher weights it can help produce images with deep blacks). There are no negative keywords this time, and the style set includes the familiar dynamic enhancer Fooocus V2 along with the new Fooocus Enhance and Fooocus Sharp styles.
Everything matters here, and we’ll start with the most important part—the choice of the base model.
Base Models (Checkpoints)
A base model, or checkpoint, is the generative model Stable Diffusion uses to turn text into images. Depending on which model you choose, the same prompt with the same seed and other settings can produce images that are stylistically similar yet distinct—or entirely different results.
As primary models, Fooocus only supports SDXL 1.0; as a Refiner it can use those as well as older SD 1.5 models. We’ll talk about refiners a bit later; for now, you can download one or more models in addition to juggernautXL_version6Rundiffusion, which Fooocus will automatically fetch when you launch run.. Save the checkpoints to Fooocus\, or to any other folder if you specify its path in Fooocus\. For example:
"path_checkpoints": "d:\\Models\\Stable-Diffusion\",
After that, click Refresh All Files; the model will appear in the list.
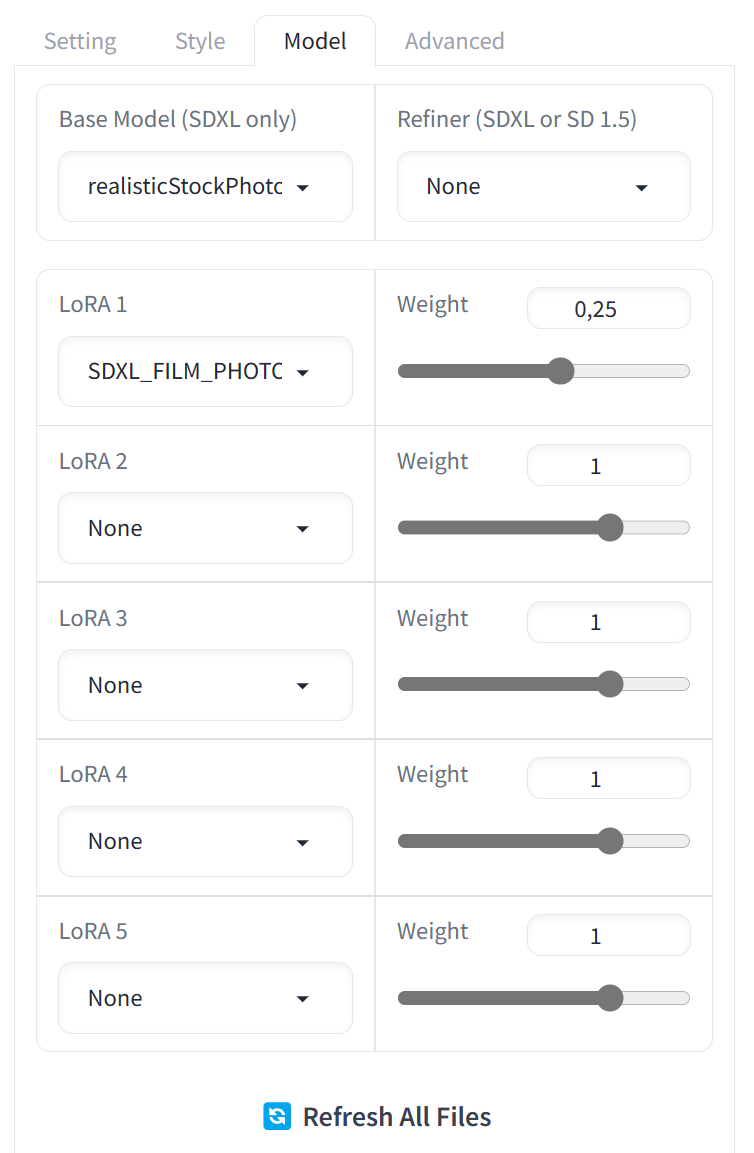
Almost all of the models are, to varying degrees, derived from the first model released by Stability AI. They’ve been augmented with new training data, and remix creators have added improvements and fine-tuning. As a result, different models can differ noticeably in both overall image composition and output quality.
Below is a brief comparison of models for the prompt “photorealistic, cinematic, close view of a redhead woman in 19th-century clothing of a woman mechanic fixing a steampunk car,” with the custom Cinematic style enabled: “cinematic angle, cinematic lighting, highly detailed, amazing, finely detailed, more realistic, Ultra HD 32k, cinematic, 4k, footage from an epic movie, clear focus, detailed character design, ultra-high resolution, perfectly composed, UHD.”
Here’s how the Bastard V1 model performed:

Below is a gallery showcasing the results from other models:
 |
 |
 |
| Models: SoftFantasy Dark Edition, CineVisionXL by Socalguitarist Easily, realisticStockPhoto v10 | ||
 |
 |
 |
| Models: RaffaelloXL Real People 10, Yggdrasil V2, and mjLnir SDXL Lightning v10 | ||
First, pay attention to the differences in composition. The “Dark” Dark Edition stands in stark contrast to the more “Hollywood” CineVisionXL; the photorealistic models go all-in on realism, Yggdrasil V2 builds atmosphere with an original color palette, and mjLnirSDXLLightning_v10—despite bungling the fingers—managed to generate an image in just eight iterations (the others needed forty).
Where to Download Models
There are plenty of base models across different types and generations, and Fooocus doesn’t support all of them. For your primary model, pick one of the SDXL 1.0 checkpoints; you can download them from Civitai. In the top-right corner of the site, look for the Filter icon and configure it as shown in the screenshot.
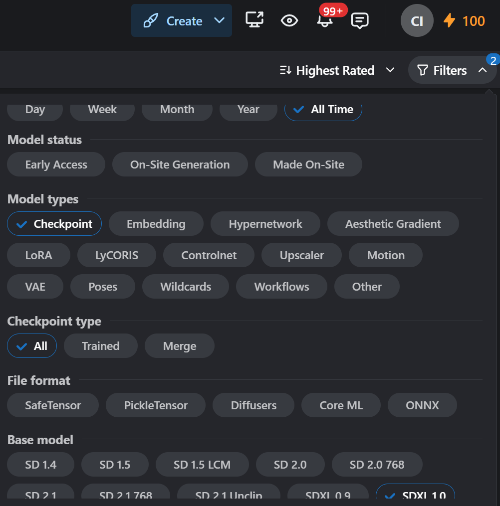
With these settings, you can display all models regardless of date (All Time), only base models (Checkpoint), or only SDXL 1.0. The last option (All) includes both trained models (Trained) and merges (Merge).
There are two types of models: trained and merged. “Trained” usually refers to models whose authors have trained them on some image dataset. However, it’s quite common to see “trained” used for merged models that the creator then fine-tuned on a relatively small dataset.
Remixes are simpler: their creators combine several different base models and LoRAs with specified weight coefficients. The simplest example is adding a “photorealistic” LoRA to a model, which further biases the weights toward photographs.
Depending on the developers’ taste, restraint, and skill, the remixes range from mediocre to genuinely compelling. There are thousands of models—trying them all isn’t feasible, even in theory. You can simply sort them by popularity, or you can follow my recommendations.
General-purpose models suited for realism
AlbedoBase XL is a well-balanced model that does it all. Many remix creators use it as their foundation.

Bastard Lord (SDXL) from Tensor.Art is one of the best models I’ve tested. Its quality is comparable to Midjourney V6. The model is a collaboration between two developers: Freek22 (creator of several models in the Norsk family) and Afroman4peace (creator of numerous models, including the excellent Hephaistos and Colossus XL).

Brookers Style XL, also known as Reality Check XL, is a realism-oriented trained model. It can produce unique results that stand apart from other models.

The Bifröst Project on Tensor.Art is a powerful model that bundles the author’s other models (including fine-tuned ones) along with some third-party models. I also recommend checking out the author’s other models on the same site or on Civitai.

CineVisionXL and, while we’re at it, the same author’s “photographic” ProtoVision XL, “3D-cartoon” DynaVisionXL, and “night” NightVisionXL are well-balanced models that deliver on their stated goals. For example, in the “cinematic” CineVisionXL even very simple prompts produce results as if the shot were staged by a Hollywood director—with matching lighting and dynamic energy.
EnvyHyperrealXL01 is a well-balanced remix with a tilt toward turbo-realism (not to be confused with straight-up realism). By the way, I’d also recommend checking out the author’s other models.

RaffaelloXL Real People — although it’s a remix, I haven’t been able to match this model’s results with any other. Its signature traits are highly detailed faces and textures, and strong micro-contrast.

Realistic Stock Photo — you already got the first version bundled with Fooocus, but a second one has since been released. It’s an excellent, well-trained realistic model. You can see the difference between versions 1 and 2 in the examples below.


SDVN6-RealXL is a model trained on facial photographs. It can produce original portraits that don’t have the usual AI-generated model look. And it doesn’t stop there: it comes with a full-fledged artistic toolkit.
There are plenty of other models worth a look; listing them all is impossible, and that’s not my goal anyway. There’s cherryPickerXL, Hephaistos NextGen, Luna Mia, SoftFantasy Dark Edition, and many other interesting models.
Specialized models: Anime
Anime-style models fall into the specialized category because they use their own syntax—a topic that merits a closer look.
In Stable Diffusion 1.5, there was only one text decoder pipeline. Overall, the model performed better when you listed keywords separated by commas.
Stable Diffusion XL uses two pipelines: the classic CLIP-ViT/L and OpenCLIP-ViT/G, which can interpret natural-language prompts. The base model released by Stability AI supports both, so derivatives built on this model work with both keyword-style tags and natural-language prompts.
Then the anime-art crowd showed up. For training data, they tapped into the image dumps from numerous booru-style sites, where almost every picture comes with a tag set: what’s depicted, how, in what style, and who the author is. And it’s all in a machine-readable format.
Accordingly, in these models the L pipeline does most of the work, while the G pipeline is largely idle. This was eventually addressed by using yet another AI for CLIP Interrogation, where the model analyzes an image and generates a text prompt tailored to the selected pipeline type.
www
CLIP Interrogation demo (L, G, and H pipelines from SD 2.0/2.1 are available).
The end result was models trained on well-structured datasets and enriched with natural-language queries generated by yet another AI.
As a result, anime-focused models respond very precisely to keyword triggers, but they can also interpret plain-language prompts (though not always reliably). If your goal is anime-style images, a specialized model will deliver higher-quality results with less effort.
There are two main anime models.
Pony Diffusion V6 XL. This is probably the most popular model: it has hundreds of styles and LoRAs. If you download the model, run a prompt, and end up with something muddy, gray, and vaguely 3D-looking, read the detailed guide at the link above, specify a style in your prompt (from the collection on GitHub), and use a specialized LoRA or one of the remixes. Just remember that the LoRAs, like the base model, must be in SDXL 1.0 format.
Animagine 3.0 — it’s worth reading the documentation for this model on Hugging Face and on the CagliostroLab website.
There are countless remix variants built on each of these two models, preconfigured to use a particular style right out of the box.
If you’re using A1111 or WebUI Forge, I recommend installing this extension, which helps prevent artifacts when generating with these models.
Refiner Models
When the first Stable Diffusion XL base model was released, the developers provided an option to use a second, auxiliary model in the final sampling steps to add fine detail and fix small artifacts left by the base model. The refiner doesn’t need to fully decode the prompt; it can work directly from the image the base model has already produced, while it’s still in latent space.
Using the refiner is pretty simple: connect it, set the weighting factor (more on that below) — profit! Or maybe not.
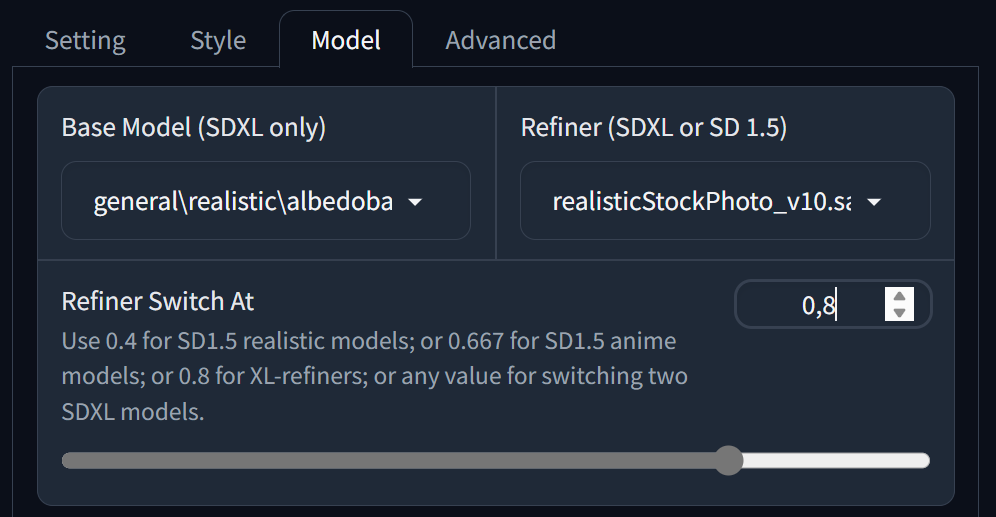
First, let me clarify how the weight works. The number specifies what portion of the work the primary model performs; the refiner handles the rest. So if you set the weight to 0.8, as in the screenshot, 80% of the generation is done by the selected model albedobase, and the remaining 20% by the model realisticStockPhoto.
With most modern models, there’s no longer a need to use a refiner to add extra detail or clean up minor artifacts as originally intended; the model authors themselves say so. That said, it’s worth remembering the creative potential of switching to a different model at an arbitrary point in the generation process—just don’t overestimate how much that really gets you.
And one last note: while Fooocus supports only SDXL as the primary model, the refiner can be either SDXL or SD 1.5.
Styles
Style selection is available on the Style tab.
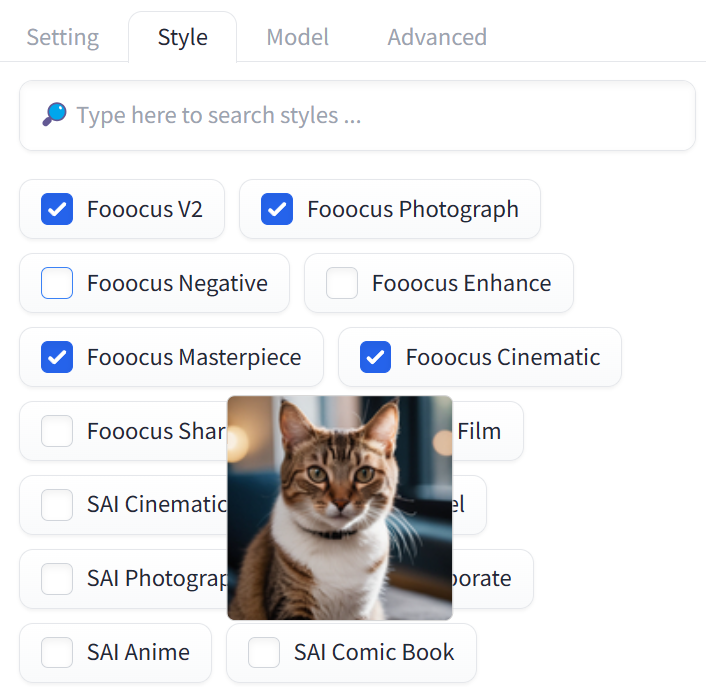
Essentially, styles are just prompt extensions made up of specific keywords. All styles are static except for the Fooocus V2 style, which uses a local GPT-like AI to expand the prompt dynamically. Each iteration is processed separately, so images within the same batch can be generated from different prompts. You can think of styles as:
style_keyword1, style_keyword2, {prompt} . style_keyword3, style_keyword4, style_keyword5
There’s no hard limit on the number of keywords, but don’t overdo it. Keep in mind the 75-token limit—once you hit it, the query string will be split into multiple chunks, and you won’t be able to control where the breaks occur.
For all subsequent tests, I disabled the default styles (notably the Fooocus V2 dynamic style), removed all negative keywords, and turned off all LoRAs and the refiner. To demonstrate different styles, I used the same prompt, the same model, and the same seed.
For style comparison, I used the prompt “photorealistic, cinematic, close view of a redhead woman fixing a steampunk car,” the BastardV1 model, and seed 1125477473. The initial resolution was 1024×1024, then upscaled 2×.
This is how the image looks with no styles applied:

The gallery below uses a mix of styles—some from the Fooocus list and others I put together myself.





And finally, I tested the dynamic Fooocus V2 style, paired with the Fooocus Masterpiece style.

Testing all the styles is a massive undertaking, but people on the internet do it regularly. For example, there’s an excellent document comparing all the styles in a large, image-rich table (its discussion is also worth checking out).
By the way, the table also includes a full explanation for each style.
LoRA adapters
Thanks to LoRAs, you can train almost any base model to capture a specific concept (for example — “rays of light in a dusty room”), characters, or styles (for example, the style of particular artists or entire art movements) — and it doesn’t end there.
There’s a class of LoRA sliders that let you, for example, change the image scale, simply by adjusting their weight within the developer-specified range (sometimes quite broad and even starting at negative values). There are also LoRAs that tell the model to add more detail or, conversely, simplify the image (e.g., the AddDetail LoRA).
For the Pony Diffusion family of models, you need to use specialized LoRAs, since these models only incorporate a small portion of the SDXL base model. There are plenty of such LoRAs on Civitai; they typically include specific styles and characters.
LoRA adapters are relatively compact—about 60–150 MB—significantly smaller than a typical base model (~6.5 GB).
For example, let’s take the same prompt: “cinematic, close-up of a redhead woman wearing 19th‑century mechanic’s clothing, fixing a steampunk car,” but add a style tag: “in the style of Esao Andrews, Esao Andrews style, Esao Andrews art, Esao Andrews.”
Here’s what the output looks like without LoRA.

And now—with it (LoRA — FF-Style-ESAO-Andrews-LoRA).

Many LoRAs work great when paired with styles. Here, I combined a LoRA with the Cinematic style.

And here, I applied the Midjourney style.

Bonus: Model Gallery
Out of curiosity, I ran generation on the same prompt with the same seed across a few dozen different models. Most of the time the outputs were quite similar, but a few models produced interesting results. Here are a few examples.
 |
 |
 |
 |
| socafaeXL, sahastrakotiXL, SorcererXL-3, xi_v10 | |||
 |
 |
 |
 |
| FenrisXL V16.4, NewdawnXL3.1 bf16, SoftFantasy Heavensfall, Better than words v3.0 | |||
 |
 |
 |
 |
| Artium v20, easelEssenceXL v10, weekendWarriorVaeXL v10, aderekSDXL v15 DPO | |||
 |
 |
 |
 |
| Altar SDXLRealistic v10, fantasyAndRealityXL v10, LahMysteriousSDXL v40, paintersCheckpointOilPaint v11 | |||
Coming up next
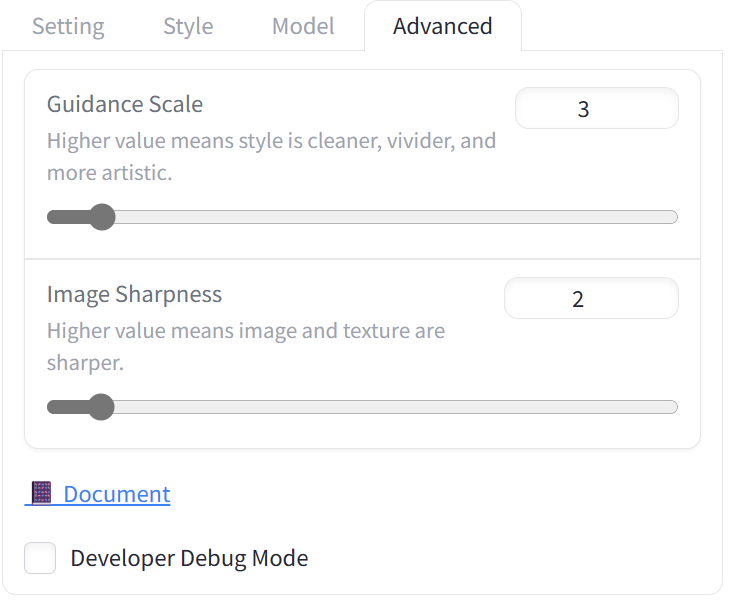
Yes, we’re still talking about the app you install and launch via run.bat, with a single input field and a Generate button—but there’s more to cover. Next, I’m going to explain how the Guidance Scale (aka CFG value) and Image Sharpness parameters influence the results (and no, Image Sharpness here isn’t about simple edge sharpening).
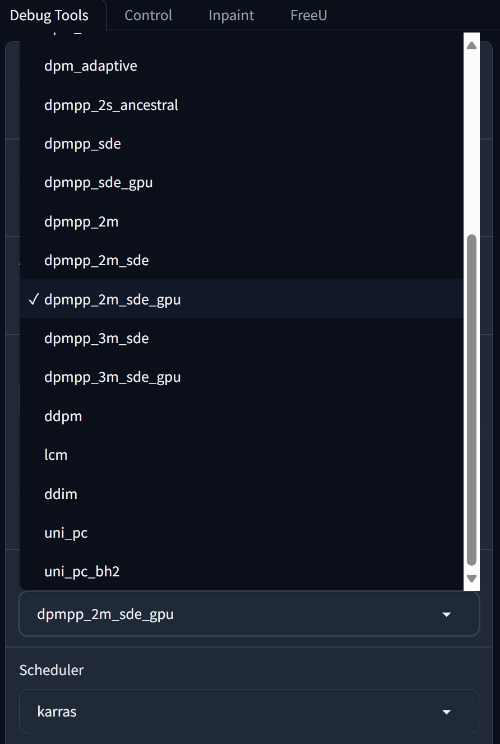
Next, we’ll discuss the different types of samplers and how they differ, as well as the LCM, Turbo, and Lightning models that can speed up generation severalfold.
Finally, after this you can move on to the next, more advanced tool — Stable Diffusion WebUI Forge. More to come!