
Open source tools for protection against DDoS (IPS), such as, Snort, are based on DPI, that is, they analyze the entire protocol stack. However, they cannot control the opening and closing of TCP connections, since they are too high in the network stack of Linux and represent neither server nor client side. This allows to bypass IPS data. Proxy servers are also involved in establishing the connection, but they cannot protect against major DDoS attacks, because they are relatively slow, as they work based on the same principle as the server. For them, it is desirable to use the equipment which, despite being not as good as the one for the back end, can withstand heavy loads.
NatSys Lab decided to follow the path of kHTTPd and TUX and implement a framework for working with HTTP in a kernel mode. So far, this framework is in alpha stage. However, a release is promised for mid 2015. Still, to understand the principles of work and play a bit with this tool, we can examine the prototype, which is quite operational.
Installation and Configuration
To assemble Tempesta, you need the source code for kernel 3.10.10 with the necessary tools. Download the source code of the project:
$ git clone https://github.com/natsys/tempesta.git
Getting Tempesta
Copy the patch and apply it:
$ cp tempesta/linux-3.10.10.patch linux-3.10.10/
$ cd linux-3.10.10
$ patch -p1 < linux-3.10.10.patchEnable the desired features. Thus, you should enable ‘CONFIG_SECURITY’ and ‘CONFIG_SECURITY_NETWORK’, disable all other LSM capabilities such as SELinux and AppArmor, and set the value of 2048 for ‘Warn for stack frames larger than’ in the submenu ‘kernel hacking’. Then assemble/install the kernel:
$ make nconfig
$ CONCURENCY_LEVEL=5 fakeroot make-kpkg --initrd --append-to-version=-tempesta kernel_image kernel_headers
$ sudo dpkg -i ../linux-image-3.10.10-tempesta_3.10.10-tempesta-10.00.Custom_amd64.deb ../linux-headers-3.10.10-tempesta_3.10.10-tempesta-10.00.Custom_amd64.deb
$ sudo shutdown -r now
Setting the stack frame size in the kernel
After rebooting, you can proceed with building Tempesta. To do this, go to the directory where we cloned it and enter the following command:
$ make
Assembling Tempesta
INFO
The argument ‘NORMALIZATION = 1’ specified for the command ‘make’ when assembling the modules of Tempesta allows to normalize HTTP traffic.
After the assembly, you can, of course, run the tool, but first let’s examine the configuration file. You can find an example of it in etc/tempesta_fw.conf. Let’ examine what is inside:
# Specify the back end, where will be sent the requests. You can specify multiple back ends, each on a separate line
backend 127.0.0.1:8080;
# Port (and when necessary, address) used by Tempesta. Again, you can use multiple addresses/ports
listen 80;
listen [::0]:80;
#Configuring the caching (enabled/disabled). If the protected back end is on the same server as Tempesta, it is better to disable it
cache on;
# Directory with the cache. It has an absolute path, which should not end in a backslash. In addition, if the path has space characters and special characters, it must be enclosed in quotes
cache_dir /opt/tempesta/cache;
# Cache size. Measured in kilobytes and must be a multiple of 4096
cache_size 262144;In addition to this configuration file, the same directory has a file ‘tfw_sched_http.conf’, which actually contains HTTP routing rules and whose content should, in theory, be included in previous file, but apparently it was left as a separate file so that the developers can later add the option to process it in the manager module. Let’s have a look at its syntax:
# Required string with module name
sched_http {
# Back end groups. The back ends must be specified in the previous configuration file. Within the group, the balancing is provided through the round-robin algorithm
backend_group static_content {
backend 192.168.1.19;
backend 192.168.1.20:8080;
}
backend_group im {
backend 192.168.1.21;
}
backend_group main {
backend 192.168.1.5;
}
# Routing rules. These rules are specified as follows:
# rule be_group field operator pattern
# where 'be_group' is the back end group defined above, 'field' is the field of HTTP header compared with the 'pattern' by using the operator. List of available fields:
# uri is a part of 'uri' in HTTP request that contains the path and string of request
# host is the host name obtained either from 'uri' or 'Host' header. The first has a higher priority
# host_hdr is only the 'Host' header
# hdr_conn is 'Connection' field in the header of HTTP request
# hdr_raw is any other field, the name of which is specified in 'pattern'
# operator can be either 'eq' to fully match 'pattern' or 'prefix' to match the beginning of the string
# If the request does not meet the current rule, it is checked against the next one
rule static_content uri prefix "/static";
rule static_content host prefix "static.";
rule im uri prefix "/im";
rule im hdr_raw prefix "X-im-app: ";
rule main uri prefix "/";
}As I already mentioned, these two files cannot operate separately, they must be combined into one, which you can do by using the command
$ cat tempesta_fw.conf tfw_sched_http.conf > tfw_main.confFinally, run:
# TFW_CFG_PATH="/home/adminuser/tempesta/etc/tfw_main.conf" ./tempesta.sh startTo stop it, use similar command with argument ‘stop’.
ModSecurity
A module is a WAF for Apache and provides the following features:
- Real time monitoring and access control;
- Virtual patching, a technology for eliminating the vulnerabilities without modifying the vulnerable application. It supports flexible language for making rules;
- Logging all HTTP traffic;
- Evaluating the security of web application
and much more.
ModSecirity can be configured both as a reverse proxy and a plug-in for Apache.
Architecture
We also should examine the internal architecture of the project.
General Information
Before examining this framework, let’s remember how is operating the similar software. Virtually all modern HTTP servers use Berkeley sockets which, despite their utility, have two major problems. The first is the excessive number of various features. For example, to limit the number of connected clients, you need, first, to allow the incoming connection by using accept(), then find out the address of the client by using ‘getpeername()’, check whether the address is in the table and close the connection. This takes more than six context switches. The second problem is that the read operation from the socket is asynchronous to the actual receipt of TCP packets, which further increases the number of context switches.
To solve this problem (as well as the problem of transferring data from kernel space to user space), the developers of Tempesta moved HTTP server to TCP/IP stack which, as it is well known, is in kernel mode. Unlike other similar projects, Tempesta does not use the disk cache, as everything is stored in RAM.
The goals of Tempesta project are as follows:
- Creating the framework with a comprehensive control over the levels of TCP/IP stack from network level and above to get flexible and powerful systems for traffic classification and filtering.
- Operating as part of TCP/IP stack for efficient processing of “short” connections, which are typically used in DDoS attacks.
- Close integration with Netfilter and LSM subsystems, which again is useful for identifying and filtering large botnets.
- High-performance processing of HTTP sessions and functionality of caching proxy to reduce the load on back end.
- Normalizing HTTP packets and forwarding them to the back end to prevent differences of interpretation on the back end and on this IPS.
Tempesta is a cross between a caching reverse HTTP proxy and firewall with a dynamic set of rules. It is implemented in the form of several kernel modules. In particular, it has synchronous sockets that do not use file descriptors (as it was implemented in the Berkeley sockets), because they work in kernel mode. As a result, this reduces the overhead costs. There was also a need to make some changes in other parts of the kernel which, by the way, improved control over TCP sockets for specifically prepared kernel modules. All incoming packets are processed in “lower halves” of interrupt handlers. This increases the frequency of receiving the necessary data in CPU cache and allows to block incoming packets and connections at the very early stages.
Tempesta has a modular structure that gives it great flexibility. It supports the following types of modules:
- Classifiers – as their name implies, they allow to classify the traffic and obtain statistical information;
- Detectors – they identify and handle the cases of overloading the back end;
- Request Managers – they distribute HTTP requests across multiple back ends;
- Universal Modules for processing HTTP packets.
Although originally Tempesta was not designed as WAF, it is not difficult to implement this feature.
Processing Packets and Connections
After receiving the package, the program first calls the function ‘ip_rcv()/ipv6_rcv()’ and the package is checked by Netfilter handlers. If it passes these handlers, it is passed further on to functions ‘tcp_v4_rcv ()/tcp_v6_rcv ()’. TCP socket callbacks are invoked much later; however, there are security-related handlers that are invoked directly from these functions, they include, for example, ‘security_sock_rcv_skb()’. These handlers are used by Tempesta to register the callbacks of filters and classifiers for the TCP level. However, synchronous sockets handle TCP at a higher level.
Tempesta network subsystem works entirely in the context of pending interrupts without using any auxiliary streams. The incoming packets are processed as quickly as possible, they barely have time to leave CPU cache. The entire HTTP cache is contained in RAM (it is loaded there from disk separately from the network subsystem) which, therefore, eliminates slow operations and allows to handle all HTTP requests in a single SoftIRQ. Some packets may be handed over to the user-mode process, which performs the classification that does not require high urgency. HTTP message may include several packets. As long as it is not processed entirely, it will not be handed over to back end.
If an HTTP request is not processed by the cache, it will be sent to back end. All operations related to this action will be performed in the same SoftIRQ, that received the last part of the request. Tempesta handles two types of connections, such as connections from Tempesta to the back end servers and connections from clients to caching server. Their handling (as well as the processing of packets) is provided by the same synchronous sockets.
Tempesta maintains a pool of persistent connections with the back end. Their persistence is ensured by standard HTTP keep-alive requests. If the connection is broken, it is restored. As a result, following a client request, the front end will not establish a new connection each time (which usually takes quite a long time), but will use the existing connection.
If a malicious link is found, it is simply removed from the hash table of connections, and all relevant data structures are cleaned. In this case, neither FIN packets nor RST packets will be sent to the client. Also in this case, the filter rules will be generated so that, in the future, we will not have to worry about this client.
Source code of HTTP parser
Normalization and Classification
As I already mentioned, there are workarounds for HTTP/IDS/IPS based on a difference in interpretation of HTTP requests by protection system and the server. Because there is a likelihood that a web application may behave incorrectly, proxy servers usually do not modify the HTTP requests. Of course, this can lead to security vulnerabilities but, under normal circumstances and with proper approach to development of a web application, it can be tolerated. For Tempesta, this is a low priority task, so instead of working code it has been provided with stubs. But even these stubs allow to assume that the developers plan to normalize URI header and POST messages.
There are several mechanisms for traffic classification; for example, Tempesta allows to register the handlers in order to use them in classifier modules:
- classify_ipv4()/classify_ipv6() – called for each received IP packet;
- classify_tcp() – called for TCP packets;
- classify_conn_estab()/classify_conn_close() – called when establishing and closing TCP connections, respectively;
- classify_tcp_timer_retrans() – should be called with forwarding TCP packets to clients; in fact, the code for this was not implemented; instead, there is a stub;
- classify_tcp_timer_keepalive() – should be called with sending TCP keep-alive packets; again, there is a stub instead of it;
- classify_tcp_window() – should be called when Tempesta chooses the size of TCP “window”; a stub;
- classify_tcp_zwp() – should be called, if the client sent a TCP packet with a zero size “window” (in this case, the server should send probing packets); a stub.
As you can see, at the time of writing this article, most of the hooks have not been implemented.
In case of HTTP traffic, there are no hooks for its classification; GFSM hooks should be used instead. Let’s take a closer look at GFSM. GFSM is generalized finite state machine. Unlike the conventional finite state machine (on which is built the vast majority of HTTP servers), a generalized finite state machine allows you to change the description of the handling process at runtime. In a conventional state machine, this description is hard-coded into the code. So, for the classification of HTTP traffic in the generalized finite state machine responsible for handling HTTP requests, there are hooks for individual processing stages.
The callbacks may return the following constants:
- Pass – packet is normal, it should be allowed to the back end;
- BLOCK – packet appears to be malicious, it should be blocked (as well as all subsequent packets from this client);
- POSTPONE – this packet is insufficient for the final decision, it should be postponed, processed and (in case of positive decision) send to the back end.
Currently, Tempesta has only one classifier module that uses only a portion of hooks (which is natural, because the others are not implemented). This module analyzes the number of HTTP requests, the number of simultaneous connections and the number of new connections from a specific client and for a specific period. The first two limits have the similar effect as the limiting module in ‘nginx’. If the client exceeds at least one limit, it will be blocked.
Caching
As I already mentioned above, one of the main goals of Tempesta (or maybe the main goal) is to provide protection against DDoS attacks. Since these attacks can be carried out by hundreds (if not thousands) of bots, any proxy server that uses the disk cache will simply suffocate from the terrible drop in performance. This drop in performance results from the architecture-based features of accessing the file system, such as the synchronization with the hard disk, search operations (optimized for files and directories and not suitable for searching within specific files).
In contrast, Tempesta uses a lightweight in-memory database that supports cache object persistence, static content and filter rules. This database can also be used to store the results of resolver, events, logs and traffic dumps.
Since Tempesta cache is stored in memory, there are no I/O operations when interacting with clients. HTTP responses from the back ends are stored in memory after they are sent to clients to accelerate their work. Moreover, they are stored entirely, including the headers, in the buffers that are directly used in the socket send queue.
All cache files are mapped to memory and locked in it to minimize the access to disk. The persistence is ensured by standard mechanisms of virtual memory manager that dump “dirty” pages from memory to disk. In addition, there are two new auxiliary streams: the first stream resets old and rarely used elements of cache, while the second stream scans the directory with cache by using ‘inotify’ interface to identify new or modified files. To load them, the stream reads these files in parts to a special memory area. Next, these parts are indexed by database and can be immediately sent to the client. On the one hand, this means that the database uses the data that has already been prepared for sending instead of using the “raw” data. On the other hand, no manipulation is required for adding the files, as everything happens at runtime.
Conclusion
All in all, this is quite a promising project. Especially since so far there are no analogues in the world of open source software. But, as it is always the case, it has its own drawbacks.
The main shortcoming results, perhaps, from the need to patch the kernel. Of course, this is offset by the small size of the patch, but still, if you modify the internal API of the kernel, the patch (and, consequently, the modules of Tempesta) will not work. Secondly, in about six months, the developers could have implemented at least some of the features, that are currently replaced by stubs. Thirdly, in the kernel mode, HTTP somehow does not contribute to the sense of security, at least, while the project is in alpha stage. And fourthly, the project is being developed by a little-known Russian company that is constantly looking for new employees. Of course, it may not mean anything, but personally, I would prefer to see a similar design from the likes of Yandex.
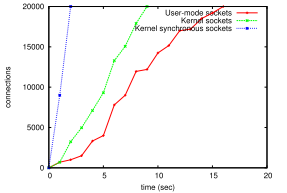
Performance in establishing connections
On the other hand, the research has shown that, due to the use of synchronous sockets, the project now works much faster than the analogues for user mode. Although, it would be a good idea to double-check the results. But the fact remains the same.

Comparing the speed of processing (requests per second) for servers based on different socket implementations
Tempesta framework is not yet ready for industrial use. However, since this is an open source, you can join its development process right now. Dare to succeed!

2022.02.16 — Timeline of everything. Collecting system events with Plaso
As you are likely aware, forensic analysis tools quickly become obsolete, while hackers continuously invent new techniques enabling them to cover tracks! As…
Full article →
2022.01.12 — Post-quantum VPN. Understanding quantum computers and installing OpenVPN to protect them against future threats
Quantum computers have been widely discussed since the 1980s. Even though very few people have dealt with them by now, such devices steadily…
Full article →
2022.02.15 — First contact: How hackers steal money from bank cards
Network fraudsters and carders continuously invent new ways to steal money from cardholders and card accounts. This article discusses techniques used by criminals to bypass security…
Full article →
2022.06.01 — WinAFL in practice. Using fuzzer to identify security holes in software
WinAFL is a fork of the renowned AFL fuzzer developed to fuzz closed-source programs on Windows systems. All aspects of WinAFL operation are described in the official documentation,…
Full article →
2022.04.04 — Fastest shot. Optimizing Blind SQL injection
Being employed with BI.ZONE, I have to exploit Blind SQL injection vulnerabilities on a regular basis. In fact, I encounter Blind-based cases even more frequently…
Full article →
2022.06.03 — Playful Xamarin. Researching and hacking a C# mobile app
Java or Kotlin are not the only languages you can use to create apps for Android. C# programmers can develop mobile apps using the Xamarin open-source…
Full article →
2022.01.01 — It's a trap! How to create honeypots for stupid bots
If you had ever administered a server, you definitely know that the password-based authentication must be disabled or restricted: either by a whitelist, or a VPN gateway, or in…
Full article →
2022.01.11 — Persistence cheatsheet. How to establish persistence on the target host and detect a compromise of your own system
Once you have got a shell on the target host, the first thing you have to do is make your presence in the system 'persistent'. In many real-life situations,…
Full article →
2022.02.09 — Dangerous developments: An overview of vulnerabilities in coding services
Development and workflow management tools represent an entire class of programs whose vulnerabilities and misconfigs can turn into a real trouble for a company using such software. For…
Full article →
2023.03.26 — Poisonous spuds. Privilege escalation in AD with RemotePotato0
This article discusses different variations of the NTLM Relay cross-protocol attack delivered using the RemotePotato0 exploit. In addition, you will learn how to hide the signature of an…
Full article →