*nix systems are by default provided with remote management tools, while the method of storing and format of configuration files allows you to rapidly distribute the updated version of settings by simply copying them to the node. This scheme will be good enough for up to a certain number of systems. However, when there are several dozens of servers, they cannot be handled without a special tool. This is when it becomes interesting to have a look at configuration management systems that allow a programmable rather than manual configuration of servers. As a result, the systems can be configured quickly and with fewer errors while the administrator will get the comprehensive report. Also, a CM system knows how to keep track of all changes in the server while supporting the desired configuration.
The ancestor of CM system is CFEngine, created in 1993 by Mark Burgess, a Norwegian scientist from the University of Oslo. Today, there are already a large number of such systems, including Chef, Puppet, SaltStack, CFEngine, Ansible, Bcfg2, synctool and others. Each of them was originally designed for specific tasks and has its specific features. In most cases, they use their own configuration language to describe the configuration of nodes and provide various mechanisms of abstraction and management styles. Some of them (declarative) describe the status of nodes, while the others (imperative) allow to control the process of implementing the changes. Mastering any of these tools will take some time. Moreover, this does not mean that selected CM system will perfectly fit all tasks, so everything will have to re-start again.
Synctool Capabilities
The development of configuration management utility to sync the clusters synctool was started in 2003 by Walter de Jong, an expert with SURFsara, a Dutch foundation, and since then it is used in the real work on large computing nodes. Its main advantage is that it is based on common sense, so there is nothing new to learn, because synctool is, in essence, just an add-on over familiar *nix tools and practices. It has no scripting language. When necessary, you can use the shell or any scripting language. Its aim is not to automate all aspects of system administration. The main task of synctool is to ensure syncing and authenticity of configuration files. That is, it is not designed for complete installation of the system, although it can be used for fast configuration of new nodes.
This is done by creating a file repository, and the master node periodically compares them with other nodes. If there are differences (for example, different checksum or creation time), it performs an update, after which it runs a special synctool-client command. By the way, it is possible to run synctool-client on the node manually. In this case, it will be check only the local copy of repository. No syncing with repository is performed on the master server, where it is always initiated by the master node.
There are three available modes of operation: deviation alert, automatic update and unconditional file update. The nodes can be managed individually, be a part of one or more logical groups or they can be managed all together. The groups can be nested.
You can expand the functionality by using your own plug-ins scripts. In this case, there is no restriction on used language. The scripts can be associated with the files to perform specific actions after updating the file; file templates can be generated on the fly (for example, IP substitution), a special type with post extension allows you to specify commands executed when updating a file (for example, restarting the service). Scripts can have a specific group of properties.
The files are distributed by using SSH (SSH key-based or host based authentication) and copying is provided by rsync. There is no need to install any agents on managed system.
Synctool operates in interactive mode. The package includes several specifically designed commands to simplify certain tasks, they are easy to use in combination with other tools. For example, dsh allows you to simultaneously execute commands on multiple nodes. Although utilities have many options, the set of core features is very small and easy to understand.
Installing synctool
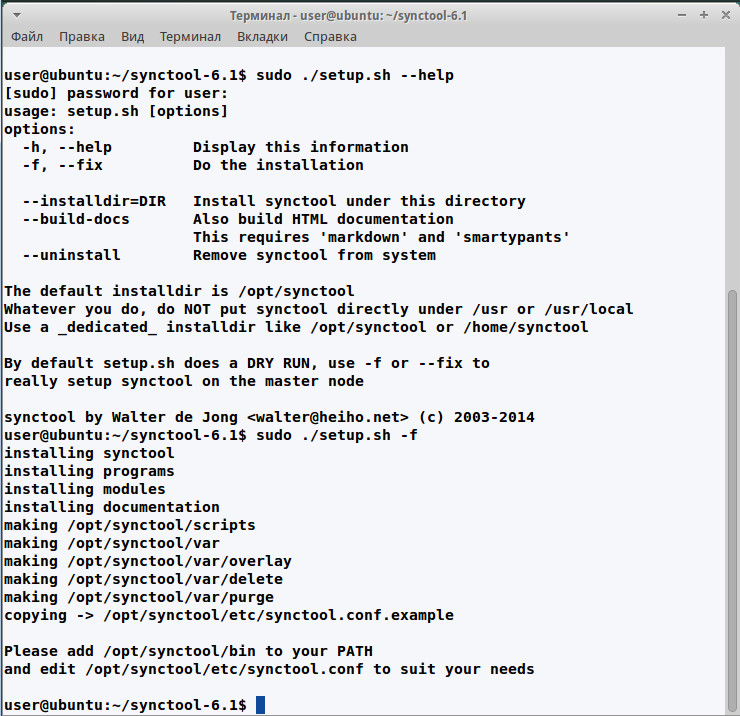
Synctool is written in Python, so its installation should not pose any problem. Specified dependencies include Python, SSH (OpenSSH 5.6+ is better), rsync and ping. Usually, all this is available in distributions. It is better to configure SSH for a password-free authentication, otherwise you will have to confirm your credentials. There are many guides on this subject in the Web. The only thing is that all utilities are connected to a remote system on behalf of root, while some systems, such as Ubuntu, have no such user by default. To avoid editing the source code, it is better to create the root user and also, don’t forget to allow it to connect via SSH. For security reasons, you should also limit sshd only to the internal network interface (ListenAddress in sshd_config), because a “glowing” port 22 is like a bait for the bots. Next, download the archive from the official web site, unpack it and execute:
$ sudo ./setup.sh -fIf you run setup.sh without -f key, this will be a “dry run”, that is a test without installation. By default, the tool is installed in /opt/synctool, and it is better to leave it that way. If this location is not appropriate, then to change it, add -installdir option. The installation directory will have several subdirectories. The scripts (they are nine) are in synctool/bin (by and large, almost all are references to synctool/sbin), it is better to immediately add this subdirectory to PATH in order to make it easier to work with.
$ sudo nano /etc/profile
PATH=$PATH:/opt/synctool/bin
export PATHNext, log out and log in again. As I mentioned earlier, there is no need to install the client software on the nodes. The master node automatically installs and updates synctool on the nodes. The executable files, that they need, are in synctool/sbin, which is synced with nodes every time you run synctool.
Installing synctool
synctool Configuration File
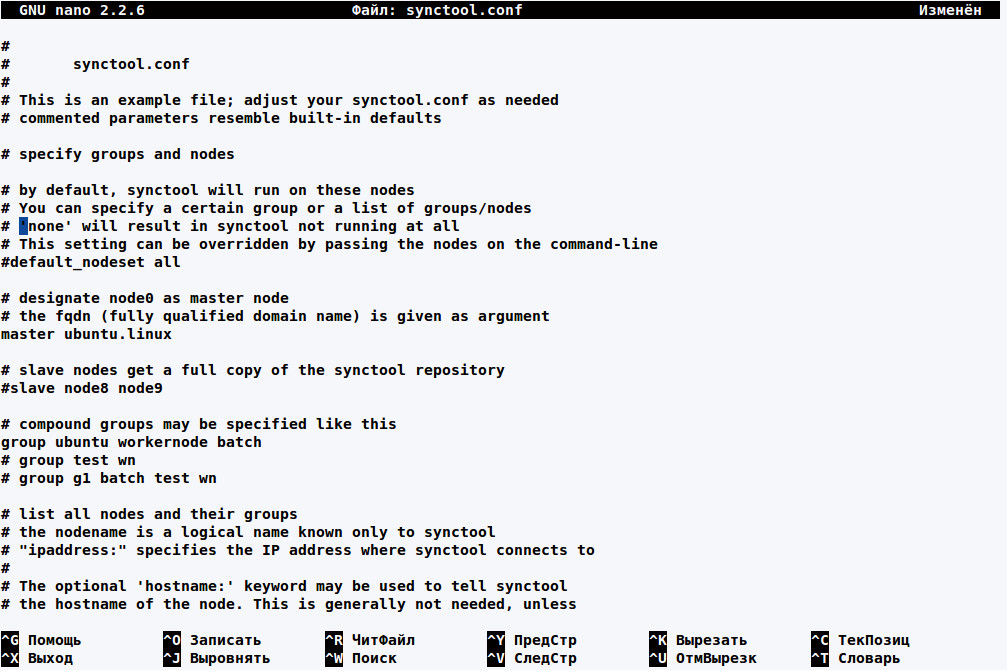
Before you begin working, you must configure synctool. All settings are specified in the configuration file /opt/synctool/etc/synctool.conf, which describes the cluster (nodes, groups, roles) and how synctool can communicate with its elements, plus logging, backup, etc. At the beginning, there is no need to try to create a complex system of multi-branch groups, as this usually leads to confusion. At any time later, once you completely figure everything out, you can rebuild the configuration. The distribution package includes an example synctool.conf.example, which you can use as a building block. There are not too many parameters, and they are all described in the [documentation] (www.heiho.net/synctool/doc/chapter4.html), although in some cases not clearly enough. Moreover, there may be several variants for writing the settings and new ones are constantly added. I will describe only some main settings.
First of all, you need to specify the master node for synctool. To do this, indicate its fully qualified domain name (FQDN) in master parameter.
master n1.cluster.org You can get the name by using synctool-config –fqdn. When the entire structure depends on a single node, this is not very good in terms of reliability, the optional parameter slave allows you to define additional nodes, that will receive the full copy of repository. The nodes are specified by using the node parameter, followed by the name of the node or nodes, group, how to connect with them and sync options.
node [ipaddress:] [hostname:] [hostid:] [rsync:<yes/no>]The node name can be any alphanumeric character. Moreover, the name should necessarily point to host name or match the DNS record, i.e. this can be any information that is easy to understand. However, synctool will search the node by the name through DNS without any further indication. For ease of use, you can specify the alias in /etc/hosts but, in this case, it will be necessary to control two files, which may lead to errors. For that reason, the developers suggest their own variant. If it is impossible to determine the indicated name through DNS or for other reasons (such as, when working offline), IP address or host name of the node are specified by using such optional parameters as ipaddress and hostname.
A node can be included in multiple groups, but the importance of groups correspond to their order of enumeration (i.e. the first one is the main group). hostid specifier is used when several nodes may have the same name. In that case, a file hosted on the target node is used to determine the current node. The node that responds when accessing the file will be checked for update.
By default, synctool is synced with all nodes. But in some cases, there is no need to do that (for example, when the nodes use a shared NFS storage), a setting rsync: will allow to block the syncing with this node.
Since the file must include the description of each node and a cluster can contain hundreds of them, there is an option to specify the range of names and parameters:
node node[1-9] ubuntu ipaddress:node[1]-cluster1
node node[10-19] ubuntu ipaddress:192.168.1.[10]If you intend to sync by using synctool and master node, it also can be specified in the node parameter, but the developers do not recommend to use this method of syncing.
In terms of synctool, the nodes are organized in groups, but, when we speak about a group, we actually mean the properties of a node. The keyword group defines the constituent groups that combine multiple subgroups into a single group:
group [..]If the subgroups do not yet exist, they are automatically defined as new/empty groups. You can also use the node name as a group. The built-in group All allows you to apply settings to all nodes. In addition, the file may contain a number of other useful parameters: ignore (allows to exclude nodes or groups), colorize (allows to colorize output), include (connects the external file to settings; this is a very convenient for a multi-branch structure managed by several administrators).
synctool.conf
To check the file, use the command synctool-config. You can test the list of nodes by using the parameter -l:
$ sudo synctool-config -l 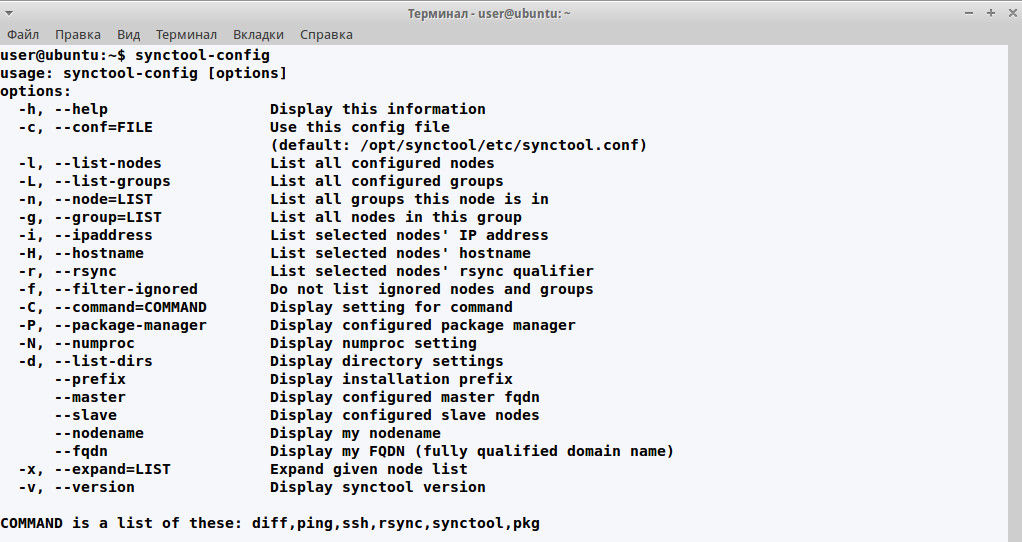
Parameters of synctool-config
Now, with these minimum settings, you can try to run synctool on the remote node:
$ sudo synctool -n node1 We will receive a response from the node meaning that everything is OK. We can try to run the task on all nodes:
$ sudo synctool
DRY RUN, not doing any updatesEach node specified in the file should give a response. Now, we have to load it with work. Going forward, I would mention one particular thing that you should keep in mind: when it is run globally, synctool requires -f option (–fix), otherwise, it will be launched in dry run mode. This allows to prevent random errors.
$ sudo synctool -fIf you specify any parameters, usually, there is no need to indicate -f.
synctool Files or Directories
The files for syncing are located in strictly defined directories that have their own purpose:
/opt/synctool/var/overlay– files that must be copied to target nodes when detecting or not detecting any difference between the file in repository and the client;/opt/synctool/var/delete– files that must be deleted. To do this, just put an empty file with necessary name;/opt/synctool/var/purge– directories that are copied to target systems “as is”, without any comparison; if the file is not available on the target system, it is deleted;/opt/synctool/scripts– directory with scripts that can be run on the target system by using dsh command.
In synctool, the name of logical groups matches the name of directory or is the extension of directory/file located in overlay subdirectories. By default, all files must have an extension. For example, the directory overlay/all contains files for all systems (even though the developers recommend to keep it empty). As an alternative, you can simply add an extension _all to the file name. This is better illustrated by example:
overlay/all/etc._group1/– files in /etc directory will be received by nodes included in group1;overlay/all/etc/hosts._group2– file /etc/hosts for group2;overlay/all/etc/hosts._all– file /etc/hosts for all;overlay/group3/etc/hosts._all– file /etc/hosts for all nodes of group3.
The symbolic references are also used during syncing. With the extension of the group, they will point to “emptiness” but, on the target system, they will show the necessary file. For example, /etc/motd is a reference to the file called file that, on the master server, has the name file._all. That is, the reference will not work but, after copying and dereferencing, everything will work as it should.
overlay/all/etc/motd._all -> file
overlay/all/etc/file._allProbably, at first, you will have to play around a bit with groups and extensions in order to understand the naming system. In case of error in the name, synctool will display something like there is no such group.
Now that the repositories are filled, we can proceed with syncing. Synctool has many parameters. For example, we need to sync a single node:
$ synctool -n node1
node1: DRY RUN, not doing any updates
node1: /etc/issue updated (file size mismatch)Or a separate file:
$ synctool -n node1 -u /etc/issue–diff option allows you to view the differences between the files as they are displayed by similarly named utility.
$ synctool -n node1 --diff /etc/issue
Using synctool
Unlike overlay, the files in purge do not use group extensions, so synctool copies the entire subtree and deletes on the target node any files that are not available in the source tree. As a result, purge is ideal for initial change in configuration or global reconfiguration of servers. After modifying the configuration file, you must restart the service. Synctool provides a simple mechanism for this: all commands, that you need to run after copying, are included in the file with the extension post. For example, in the repository, we have a configuration file of Apache web server:
overlay/all/etc/apache/apache.conf._allTo restart the service, create a file overlay/all/etc/apache/apache.conf.post with the following content:
service apache2 reloadand make it executable:
$ sudo chmod +x apache.conf.postIn the example, the script has no extension of the groups and, therefore, it will be relevant for all. You can use it, when you need to perform various actions on the nodes (apache.conf.post _ubuntu). By default, post script is run in the same directory that hosts the configuration file. The parameters of some configuration files can be generated dynamically (for example, by specifying IP address of the node), you can upload the file individually for each node, but if there are many systems, this will not be much fun. To generate such configuration files, you can use a template, i.e. a file with the extension _template. It is provided together with a _template. Post script that runs synctool-template, a special utility for generating the configuration file on the remote system. When it is run, _template.post script computes the value of variable and exports it by using export feature (the variable can have any name, or there may be several variables):
export VALUE
/opt/synctool/bin/synctool-template "$1" >"$2"In the template, simply insert @VALUE@ in the desired location. synctool-template will get the value of the variable and write it to the file.
Synctool Utilities
Synctool package includes several utilities. Their names start with dsh or synctool. The former allow to perform certain tasks on remote systems, while the latter are directly related to the various components of synctool. Some of them have an auxiliary role and, usually, must be launched manually. The others are more interesting. The names of nodes and groups come from synctool.conf. Therefore, you need a minimum of parameters to run them. For example, dsh-ping allows you to check what nodes are responding. If run it without parameters, it will query all systems:
$ dsh-pingAll synctool utilities have similar options, so almost everything that has been said about dsh applies to others as well. For example, -q and -a allow to make the output less “wordy”, while -v, on the contrary, provides for a detailed output.
But the most remarkable utility in the first list is actually dsh itself, which is sort of command manager that allows you to execute commands and scripts on a group of nodes:
$ dsh uptimeor on a separate node and group:
$ dsh -n node1 ifconfig
$ dsh -g ubuntu dateBy creating a script in the scripts directory, we can easily run it at any node (there is no need to specify the full path):
$ dsh -g ubuntu script.sh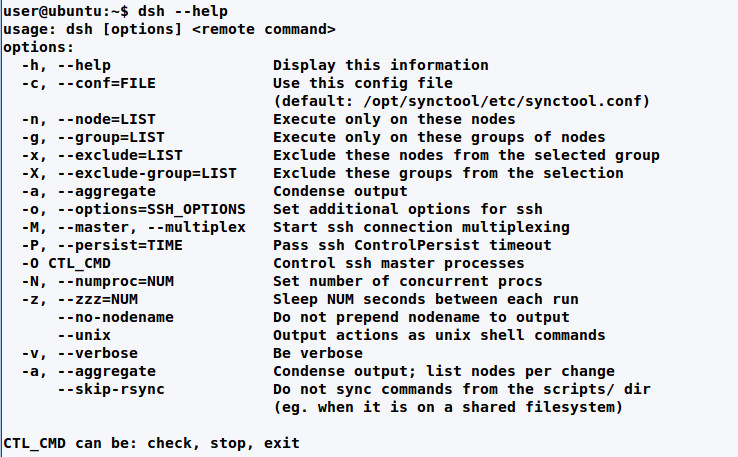
dsh parameters
After the start, the execution begins simultaneously on all nodes. In some cases, this is not necessary, so you can limit the number of processes by using –numproc, while -z allows you to specify the delay between commands for different nodes. To run only one process at a time:
$ dsh --numproc=1 uptimeTo do the same but with a five-second delay:
$ dsh -z 5 uptimeDsh-pkg, a package manager, is actually a universal wrapper over all popular tools used for installing applications in Linux and BSD. Therefore, you can control any of them by using only a single command and a set of arguments. This is useful when the group includes nodes with different operating systems. By default, the manager is detected automatically but, in some cases, it can be specified manually in synctool.conf:
package_manager apt-getBy using dsh-pkg, it is very easy to make any operation on remote systems:
$ sudo dsh-pkg -n node1 --list
$ sudo dsh-pkg -g ubuntu --install wget
$ sudo dsh-pkg --update
$ sudo dsh-pkg -upgradeThe last two commands will update the package lists and install the updates on all systems.
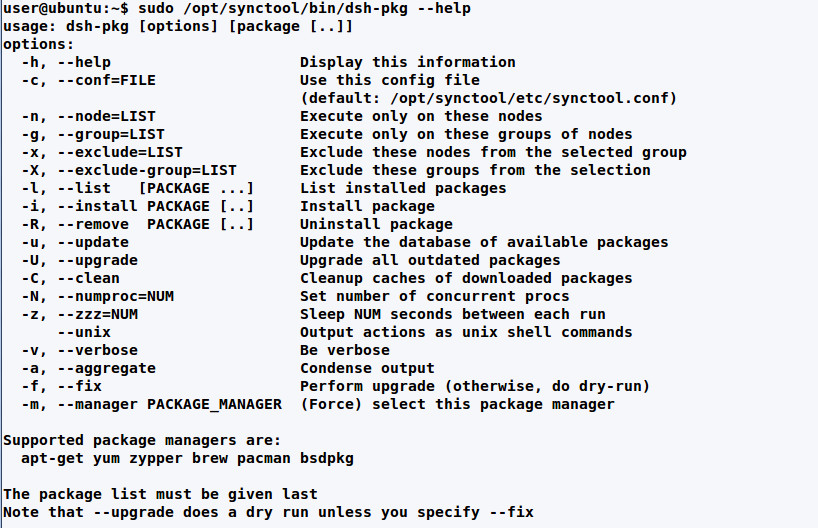
Parameters of dsh-pkg
Conclusion
I cannot say that synctool is particularly complex. To get familiar with its basic features, all you need is to experiment for a couple of hours. As a result, you will have a user-friendly and reliable tool for managing a large number of servers.

2022.06.01 — WinAFL in practice. Using fuzzer to identify security holes in software
WinAFL is a fork of the renowned AFL fuzzer developed to fuzz closed-source programs on Windows systems. All aspects of WinAFL operation are described in the official documentation,…
Full article →
2022.02.09 — F#ck da Antivirus! How to bypass antiviruses during pentest
Antiviruses are extremely useful tools - but not in situations when you need to remain unnoticed on an attacked network. Today, I will explain how…
Full article →
2022.06.01 — Routing nightmare. How to pentest OSPF and EIGRP dynamic routing protocols
The magic and charm of dynamic routing protocols can be deceptive: admins trust them implicitly and often forget to properly configure security systems embedded in these protocols. In this…
Full article →
2022.12.15 — What Challenges To Overcome with the Help of Automated e2e Testing?
This is an external third-party advertising publication. Every good developer will tell you that software development is a complex task. It's a tricky process requiring…
Full article →
2022.02.15 — EVE-NG: Building a cyberpolygon for hacking experiments
Virtualization tools are required in many situations: testing of security utilities, personnel training in attack scenarios or network infrastructure protection, etc. Some admins reinvent the wheel by…
Full article →
2022.01.12 — First contact. Attacks against contactless cards
Contactless payment cards are very convenient: you just tap the terminal with your card, and a few seconds later, your phone rings indicating that…
Full article →
2022.04.04 — Fastest shot. Optimizing Blind SQL injection
Being employed with BI.ZONE, I have to exploit Blind SQL injection vulnerabilities on a regular basis. In fact, I encounter Blind-based cases even more frequently…
Full article →
2023.03.26 — Attacks on the DHCP protocol: DHCP starvation, DHCP spoofing, and protection against these techniques
Chances are high that you had dealt with DHCP when configuring a router. But are you aware of risks arising if this protocol is misconfigured on a…
Full article →
2022.01.12 — Post-quantum VPN. Understanding quantum computers and installing OpenVPN to protect them against future threats
Quantum computers have been widely discussed since the 1980s. Even though very few people have dealt with them by now, such devices steadily…
Full article →
2023.07.20 — Evil modem. Establishing a foothold in the attacked system with a USB modem
If you have direct access to the target PC, you can create a permanent and continuous communication channel with it. All you need for this…
Full article →